Groowy脚本实现业务场景下动态性规则的实践
前言:
在复杂的业务中我们往往会采用分层的思想来降低每一层的复杂度,应用层还会采用一些设计模式来预留出对于未来的扩展;在面对
复杂和易变的业务场景下,作为开发者,我们更期望程序框架底座能够保持稳定,而对”扩展”更期望可以做到能快速响应业务需求的变化和做到隔离性;
由于程序语言的特性,有些语言不能做到实时热编译和部署,需要借助其他工具来实现这一个效果,在jvm平台上Groovy脚本语言就非常适合这种场景。
接下来以一个具体的业务需求来作为“引子”,来展开是这个需求实现过程中的一些思考和实践;
需求背景
原始需求简化后得出的核心目标就是对业务数据进行巡检,本身从功能上来讲比较简单;在系统设计出发的时候就明确了本次的功能目标:
- 向上会抽象出巡检功能的核心领域,并且支持扩展
- 向下会设计出基础设施层来作为支撑
向上这一部分工作开展的比较顺利,因为是基于现实诉求抽象公共特性/接口;但是向下这一部分设计在落地的时候遇到一些问题,有三个阶段分别是:
- 采用手动编译java代码
- 采用开源框架编译加载java代码
- 使用Groovy动态脚本
设计评审
在实现这个需求的时候,做技术方案设计评审的时候,我提供了两种实现基础设施层的技术方案:
第一种是通过easy-rules提供出一个一个散列开的业务校验规则执行器,这样做的优点是在于技术成本最低,且代码可读性好,但是没有动态编译执行的能力
第二种是通过引入动态语言实现,这样做的优点是程序具有动态编译执行的能力,缺点是在于技术成本略高,Groovy脚本语言需要一定的学习成本
最后的技术评审经过大家的沟通交流最后决定采用第一种方案来进行实现;
方案实施
在按照第一种方案进行实施的时候,遇到一个问题,代码的重复度太高;因为业务需求的本质就只是对比,因此最开始想采用反射来降低代码的重复度,将需要检查的字段放在Map进行处理;
在继续沿着这方面思考,就想到了既然是用Map来获取校验规则,那可不可以将校验规则写入配置中心或者数据库,再进行动态加载楠;
沿着这个思路开始查找java文件进行动态编译的框架joor,在进行快速验证的时候发现joor可以做到对java文件的动态编译,但是在JDK8上有部分编译错误无法实现业务的扩展性;
这个时候似乎只有一种选择了,就是采用Groovy来进行实现
Groovy使用
整体执行流程

在流程中抽象的比较方法是作为所有动态脚本的父类,默认采用了反射的反射来或者Object中指定的字段
DynamicUtil的设计
从四个问题开始入手:
- 如何简化Groovy的学习成本,从而推广出去?
- 如何保证性能?
- 如何保证动态脚本的安全性?
- 如何保证动态脚本的代码质量(动态脚本的单元测试如何进行)?
对于如何简化Groovy的学习成本?
项目初期可以采用GroovyClassLoader来执行Java脚本
- DynamicUtil
public class DynamicUtil {
public static void main(String[] args) throws Exception {
GroovyClassLoader groovyClassLoader = new GroovyClassLoader();
String helloScript = "package com.agmtopy.source.groovy;\n" +
"\n" +
"class Hello {\n" +
" public String method(String name) {\n" +
" System.out.println(\"hello, \" + name);\n" +
" return name;\n" +
" }\n" +
"}\n";
Class helloClass = groovyClassLoader.parseClass(helloScript);
GroovyObject object = (GroovyObject) helloClass.getDeclaredConstructor().newInstance();
Object ret = object.invokeMethod("method", "world"); // 控制台输出"hello, world"
System.out.println(ret.toString()); // 打印world
}
}
- Hello.java
package com.agmtopy.source.groovy;
class Hello {
public String method(String name) {
System.out.println("hello, " + name);
return name;
}
}
可以看到在上面这个例子中,我们执行的脚本就是java语法规则的脚本;这样如何简化Groovy脚本的问题就可以得到解决;
在整个执行框架稳定以后,还是需要推广Groovy脚本,java语法的脚本只是一个中间过渡方案!
如何保证脚本的执行性能?
这里的性能指的是两方面:编译和执行,我们先来看Groovy是如何编译脚本的
public Class parseClass(final GroovyCodeSource codeSource, boolean shouldCacheSource) throws CompilationFailedException {
//获取cacheKey:scriptTest+name 进行MD5
String cacheKey = genSourceCacheKey(codeSource);
//sourceCache是一个类似与Map类型的类
return sourceCache.getAndPut(
cacheKey,
key -> doParseClass(codeSource),
shouldCacheSource
);
}
private Class doParseClass(GroovyCodeSource codeSource) {
validate(codeSource);
Class answer; // Was neither already loaded nor compiling, so compile and add to cache.
CompilationUnit unit = createCompilationUnit(config, codeSource.getCodeSource());
//省略...
//创建ClassCollector,class类属性相关的收集对象
ClassCollector collector = createCollector(unit, su);
unit.setClassgenCallback(collector);
//开始执行编译命令
unit.compile(goalPhase);
answer = collector.generatedClass;
String mainClass = su.getAST().getMainClassName();
for (Object o : collector.getLoadedClasses()) {
Class clazz = (Class) o;
String clazzName = clazz.getName();
definePackageInternal(clazzName);
//设置到classCache中
setClassCacheEntry(clazz);
//设置为answer
if (clazzName.equals(mainClass)) answer = clazz;
}
return answer;
}
在上述代码中,执行流程如下
doParseClass() -> createCollector() -> unit.compile(goalPhase) -> ClassCollector.call() -> ClassCollector.createClass()
创建class对象的过程是在ClassCollector.createClass方法中,在这个方法中可以看到最后是调用的java.security.SecureClassLoader#defineClass()
- ClassCollector.createClass
protected Class createClass(byte[] code, ClassNode classNode) {
BytecodeProcessor bytecodePostprocessor = unit.getConfiguration().getBytecodePostprocessor();
byte[] fcode = code;
if (bytecodePostprocessor!=null) {
fcode = bytecodePostprocessor.processBytecode(classNode.getName(), fcode);
}
//GroovyClassLoader extends SecureClassLoader
GroovyClassLoader cl = getDefiningClassLoader();
//这里通过SecureClassLoader.defineClass 来进行加载
Class theClass = cl.defineClass(classNode.getName(), fcode, 0, fcode.length, unit.getAST().getCodeSource());
this.loadedClasses.add(theClass);
//省略...
return theClass;
}
这里还有一个点是在创建GroovyClassLoader时,都是通过new InnerLoader的方式来创建
return java.security.AccessController.doPrivileged((PrivilegedAction
) () -> new InnerLoader(GroovyClassLoader.this));
这是因为Class对象是通过ClassLoader+class的方式来定位确定唯一一个类的,InnerLoader每次都会创建一个新的对象,这样可能会导致Metaspace内存溢出,虽然在Groovy3.0以后针对这个问题已经进行过优化了,但是还是强烈建议通过内存将脚本编译后的GroovyObject缓存下来,本身脚本的再次编译和加载都是一个较为消耗性能的动作;
我们下面继续对执行性能来进行分析,在网上大多数资料对于Groovy的脚本执行性能的分析,github中关于这方面的issue也比较少,并且大部分是针对与Groovy和Java进行对比的;
下面有几个关于Groovy脚本执行的建议:
- 尽量使用静态类型,由于Groovy是动态语言,在将动态特性编译成为静态语言时是比较消耗性能的
- oracle官方对于Groovy的5条性能建议
如何保证动态脚本的安全性?
如何保证动态脚本的安全性?其实也是分为两个方面考虑的:
- 执行安全性
执行安全性指的是在执行脚本时是否会影响到我的宿主进程?如何规避这种风险?
- 脚本本身的安全性
脚本本身的安全性指的是脚本语义是否正确/正常以及可信
下面对着两方面进行分析和设计:
脚本执行的安全性方面最主要的考虑是错误的脚本是否会影响到主进程的执行?主要从下面几个方面考虑:
- 内存
内存主要还是考虑堆栈内存即可,一个是成员变量的空间分配,一个是while造成死循环使栈溢出等;可以在定义GroovyClassLoader时进行排除
final SecureASTCustomizer secure = new SecureASTCustomizer();// 创建SecureASTCustomizer
secure.setClosuresAllowed(true);// 禁止使用闭包
List<Integer> tokensBlacklist = new ArrayList<>();
tokensBlacklist.add(Types.**KEYWORD_WHILE**);// 添加关键字黑名单 while和goto
tokensBlacklist.add(Types.**KEYWORD_GOTO**);
secure.setTokensBlacklist(tokensBlacklist);
secure.setIndirectImportCheckEnabled(true);// 设置直接导入检查
list.add("com.alibaba.fastjson.JSONObject");
secure.setImportsBlacklist(list);
- 线程
对与线程方面的考虑主要是执行线程需要使用单独的线程池进行处理,这样做的目的是防止动态脚本的执行线程阻塞业务线程;第二个是动态脚本中应该禁止使用线程池来进行处理,这方面的考量主要是基于脚本业务代码尽量的要简单高效和可读性,引入线程池会增加脚本的复杂度和可维护性
- 数据库/资源的管理
对与数据库和其他资源的访问,我是持有拒绝的态度,主要观点还是和脚本中实现线程池类似,还有一点是脚本中进行数据变更和资源处理缺少了代码版本控制这一个环节;
脚本本身的安全性主要指的是脚本开发/提测/上线整个流程的安全和监控性,在这方面Vivo提供了一套内部使用的流程如下:
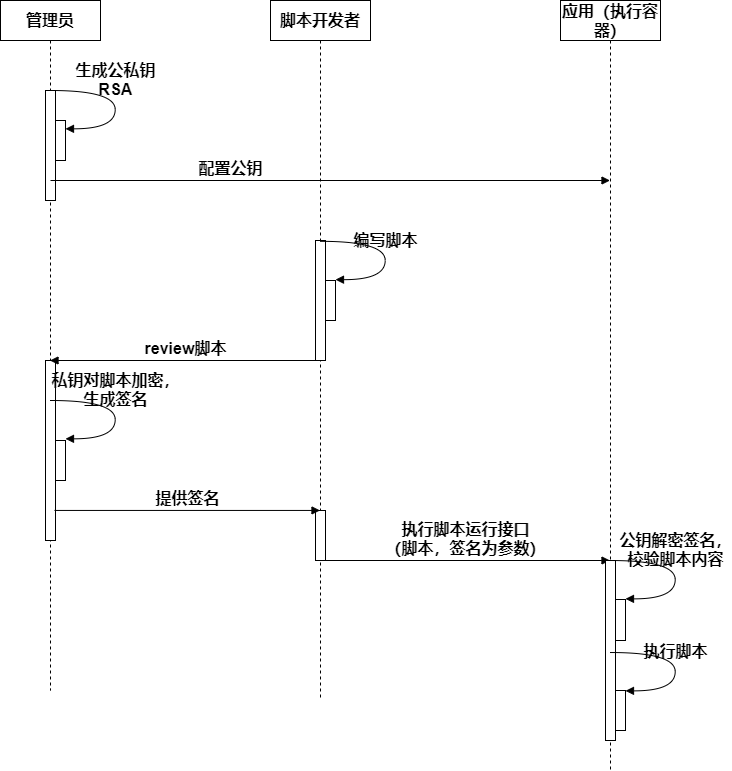
在这个过程中,除了code review部分需要开发者进行参与,其他部分都可以依托CI/CD工具实现自动化执行;
有了这样一个流程,其实是可以解决脚本本身的安全性的问题的;
如何保证动态脚本的代码质量?
动态脚本的代码质量如何进行保证,一方面是可以通过良好的code review机制来提高质量,另外一方面是需要建设好单元测试框架;
如何建立好动态脚本的单元测试?
首先是方便,在开发人员的角度一个工具只有在足够的简单方便的情况下才会乐意去进行使用,其次是流程规范.
目前执行的过程是在特定的测试包下,开发脚本,然后进行单元测试,在单元测试通过后在写入数据库中;
后续实践出更好的方案在进行更新
小结
以上通过Groovy实现了动态特性的同时引入了一些尚未解决的问题:
执行性能/单元测试,后续在实践过程中也会对这些问题持续的进行更新.

