分布式数据库系统原理
引言
为什么需要分布式?
- 处理逻辑
- 功能
- 数据
- 控制
对于这个的理解应该是:
- 处理逻辑:对应应用实例或者算法之类的,单点无法满足某些需求(AP)
- 功能:对于功能的分布式划分主要是体现在微服务的拆分上,不同的功能拆分成为不同的服务
- 数据:对于数据的拆分主要是单点数据服务无法满足要求的情况下,进行拆库拆表
- 控制:这个暂时不能理解?控制是否为程序或者算法的同义楠?
什么是分布式数据库?
物理上分布不同地方,通过计算机网络逻辑上相互关联的数据库
主要的问题
- 数据如何选择分片?
- 分布式事务的实现?
- 性能问题?
如下图:
集中式数据库模型与分布式数据库模型

可以看到集中式数据库就是一个标准的应用分层,以MySql为例
界面: 提供不同语音的MySql Drive
控制: 连接校验
编译: sql解析
执行: innodb存储引擎处理
数据访问:MySql内核处理
一致性: 各种Lock和log

可以看到分布式数据库系统需要从三个不同的方面进行考虑:物理分布<B>异构性<B>自治性
- 物理分布:指的是组成分布式系统的服务可以在物理上隔离,可以不需要在通一台硬件机器上运行
- 异构性:指的是各个服务允许使用各自的协议来提供服务,这一点在工业级的分布式数据库上应该没有实现,还是遵守相同协议来降低软件复杂度
- 自洽性:各个服务本身就可以单独对外提供服务,不用依赖其他系统,这一点常用的分布式系统较为不同
基本概念
- DBMS
DBMS-关系数据库的概念是一组结构化的数据,它是出于我们对现实世界建模的映射,一个关系数据库是以表格形式表达数据的数据库.
分布式数据库设计
有两种分布式数据库的设计方法:自顶向下的方法和自底向上的方法,这也是软件领域设计的两种通用设计方法,例如我们在设计系统的时候基于底层功能实现还是上层战略定位来进行的往往会得到不同的演进路线;
- 自顶向下:指的是在设计的时候就考虑不同的实例去支持局部的全局概念模型
- 自底向上:指的是将多个数据库中的信息集成为一个紧密相连的多数据库系统,常用于数据仓库/数据湖
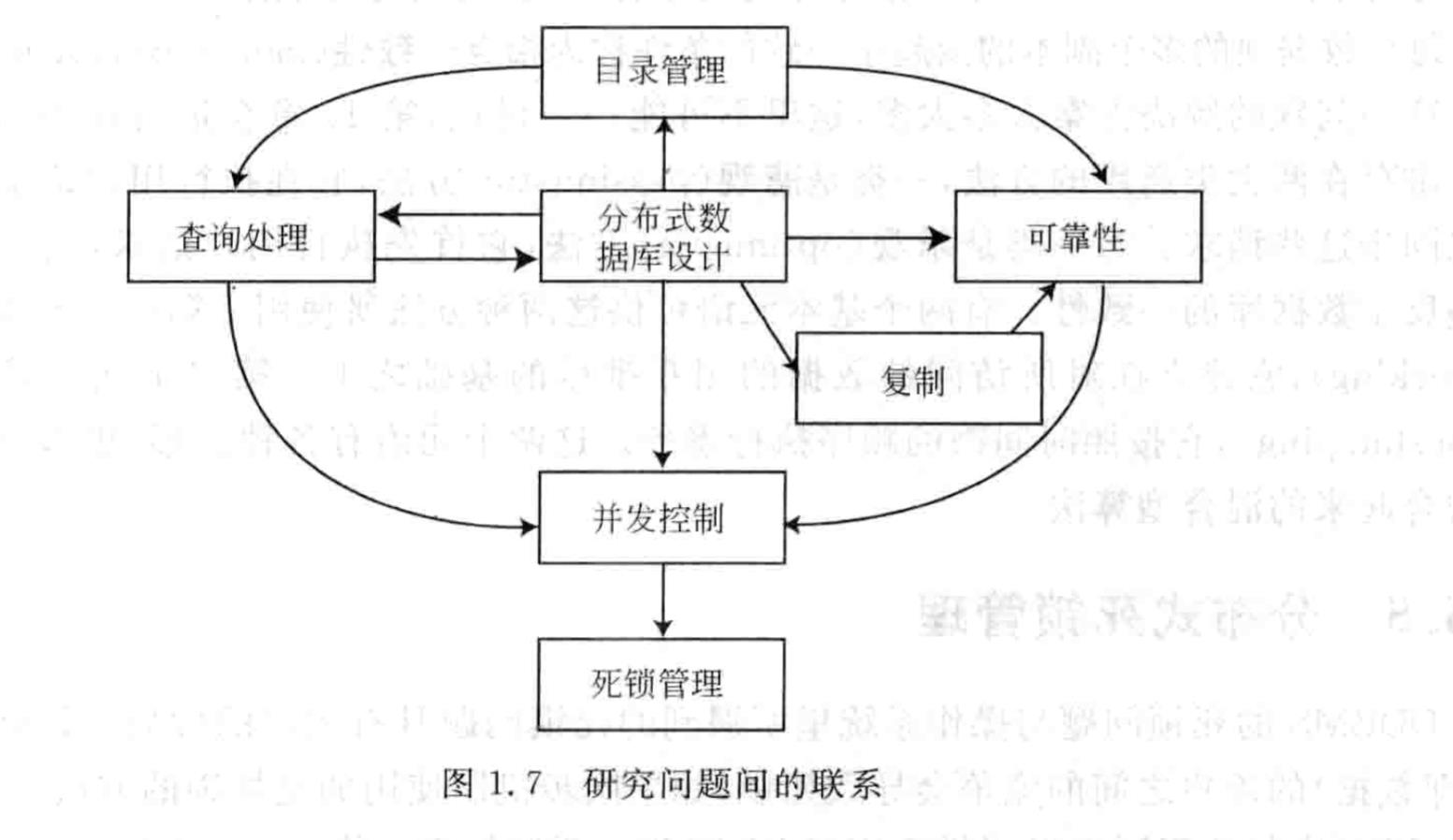
分布设计的研究问题
- 如何得到正确的分片结果?
首先,数据分片有两种维度来进行,一种是垂直分片按照业务领域进行划分,一种是水平进行分片按照特定规则来进行划分;我们会重点研究采用水平模式的设计方案.
专业的分布式数据库的数据划分好复杂,会去考虑数据的分片是按照某些条件来进行的,既要保证数据的分片又要保证数据的’亲和性’;一大段一大段的高阶函数~😳😳😳

