redis底层数据结构分析
redis底层数据结构分析主要是根据《Redis5 设计与源码分析》一书的章节而来,参考对照代码版本为6.2,源代码的编译和部署可以查看上一篇文章
redis底层数据结构可以划分为
- 简单动态字符串
- 跳跃表
- 压缩列表
- 字典
- 整数集合
- quicklist
- stream
这七种数据类型,下面分别对这七种数据类型进行分析
简单动态字符串
数据结构
简单动态字符串又被称为SDS,几乎贯穿redis中所有的模块。redis中重新设计字符串的原因是由于C语言中的char*,不满足redis中的一些常用操作例如追加字符、
计数等。
-
char*
在C语言中定义的字符串结构为:字符+字符结尾,例如"hello world!/n",而/n就是字符结尾,这样的结构不满足redis所需要的快速追加和计数操作 -
SDS
SDS结构是一个可以描述字符串类型(redis内部用于区分长度)、字符串长度、字符指针的类型,下面是一个具体的SDS的定义
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};可以看到SDS的类型还是*char,但是在内部重新定义了len-占用长度、alloc-最大长度、flags-标识等。
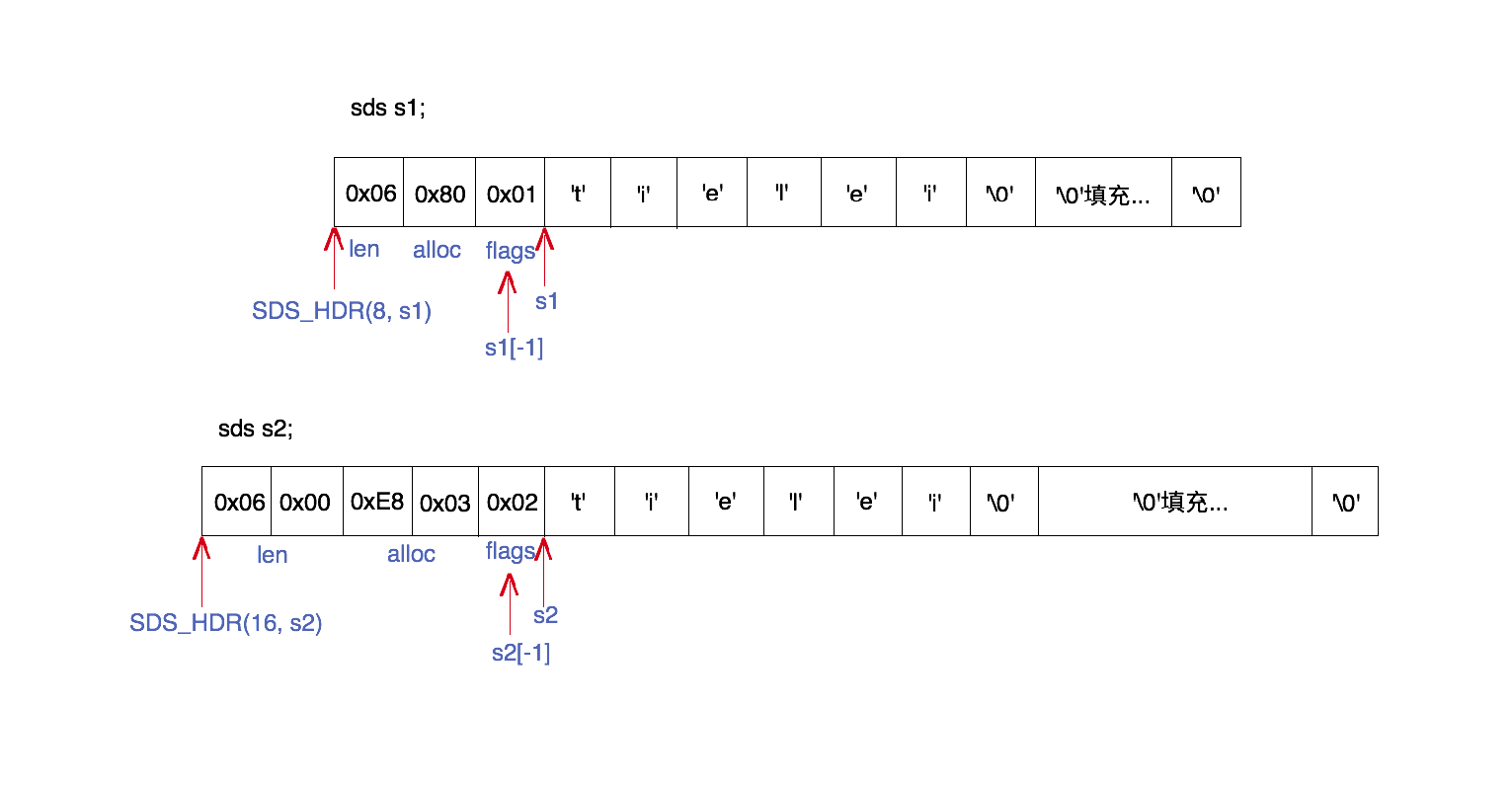
在这张图中的sdshdr8、sdshdr16,flags的低三位存储的是SDS的类型,高5位没有含义,在SDS5中高5位存储的是长度。
实际存储数据的是buf[],buf[]是一个柔性数组,柔性数组指的是数据结构和内容在内存上是连续的,这样的结构查询更快速(因为不需要额外进行指针操作)
使用attribute让编译器以紧凑模式进行内存分配,这样可以节省flags的3个字节,默认内存分配是以4个字节进行分配的
- 小结
关于SDS需要记住的tags:
- [继承] 继承于char*
- [类型] 是一种动态的字符串,根据字符的长度可以分配不同的SDS类型
- [组成] 由于len、alloc、flags、buf[]构成
- [紧凑] 紧凑模式分配类型
操作
SDS-动态字符串具有的操作分别有增删改查这几种,其中删除的设计比较特别。
- 删除
SDS的删除是通过sdsclear来实现的,直接设置len为0的方式来实现
/* Modify an sds string in-place to make it empty (zero length).
* However all the existing buffer is not discarded but set as free space
* so that next append operations will not require allocations up to the
* number of bytes previously available. */
void sdsclear(sds s) {
sdssetlen(s, 0);
s[0] = '\0';
}- 增加
增加机制可参考下图
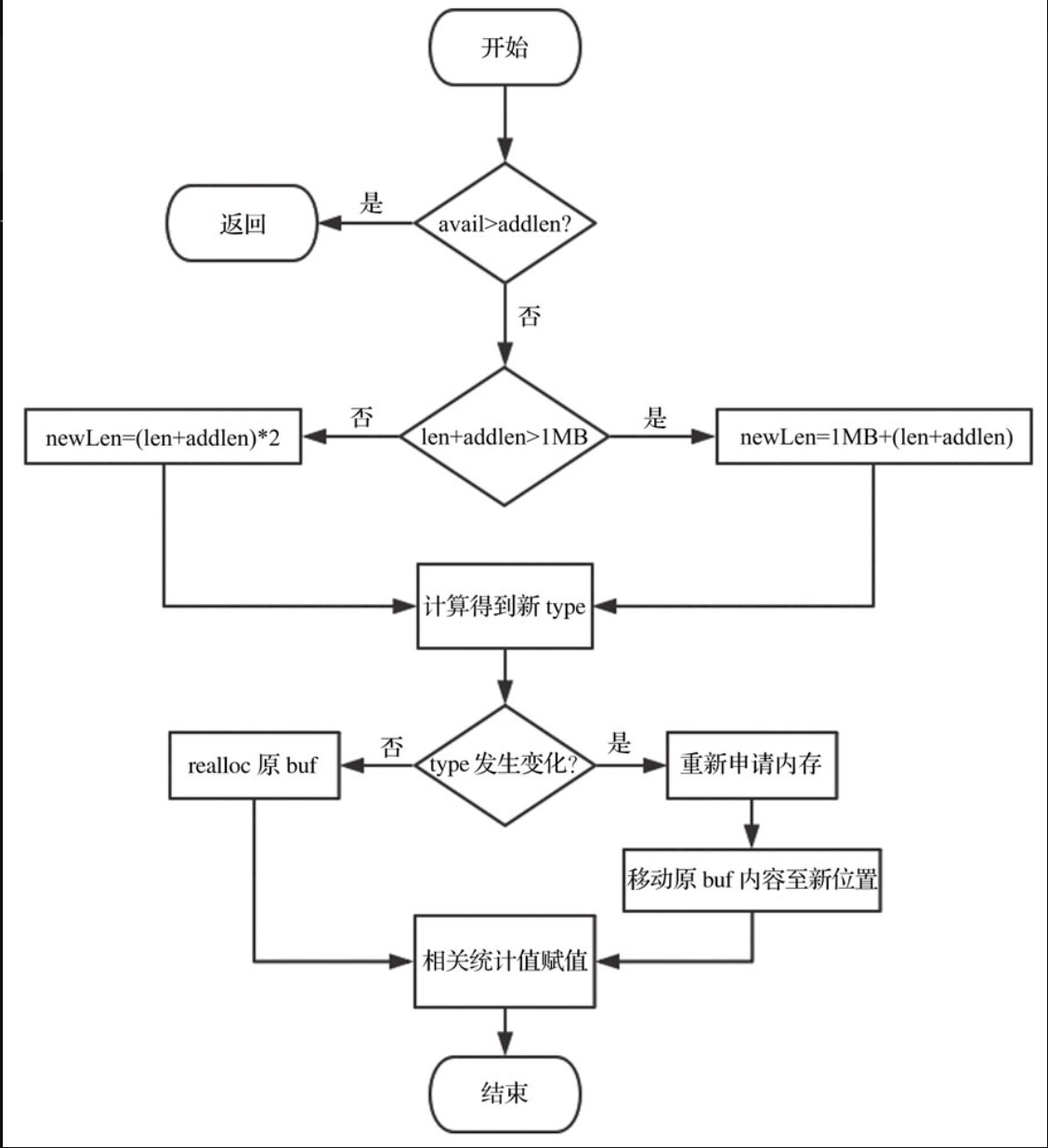
主要是进行两个判断
- 判断是否需要进行扩容
- 判断是否需要进行类型更改
默认情况下是不会使用SDS5的类型,因为Redis认为扩容是一种常见的操作,因此SDS5很大的几率会更新成为SDS8类型.
跳跃列表
数据结构
跳跃列表指的是通过维护一个多层的链表结构来实现快速查找的数据结构
跳跃列表的解释.
下面是一个跳跃列表的数据结构
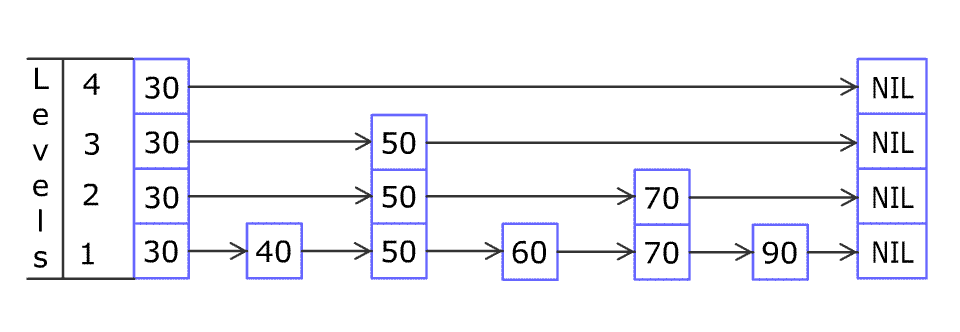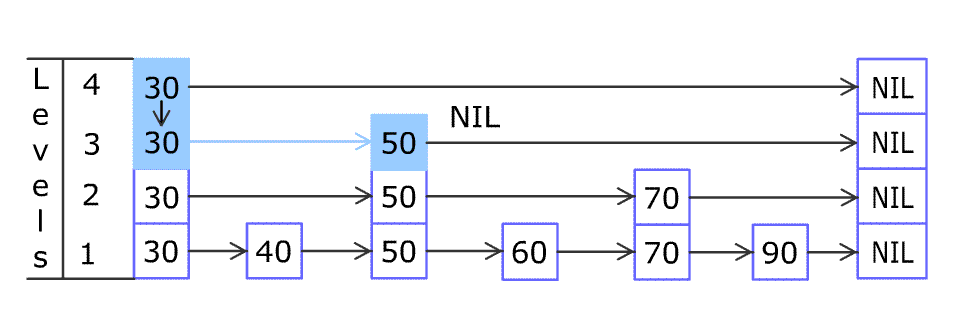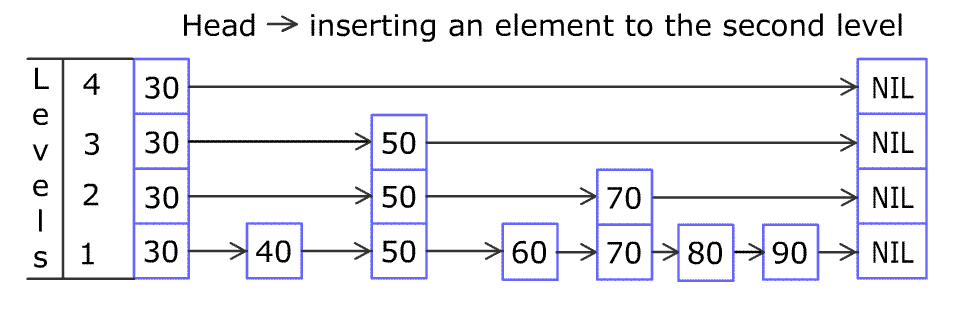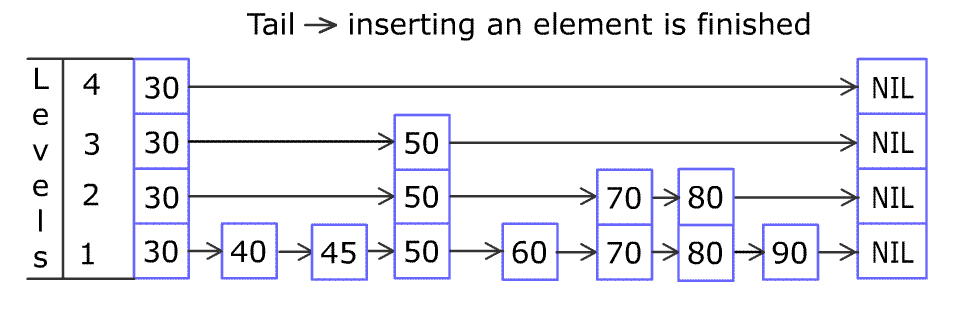
通过将有序集合的部分节点分层,由最上层开始依次向后查找,如果本层的next节点大于要查找的值或next节点为NULL,则从本节点开始,降低一层继续向后查找,依次类推,如果找到则返回节点;否则返回NULL。采用该原理查找节点,在节点数量比较多时,可以跳过一些节点,查询效率大大提升,这就是跳跃表的基本思想。
redis中的跳跃列表主要是由两个元素进行实现zskiplistNode、zskiplist,下面来详细分析一下这两个元素的源代码
- zskiplistNode
/* ZSETs 所使用的特殊版本的Skiplists */
typedef struct zskiplistNode {
//字符串类型ele
sds ele;
//用于存储排序的分值,最底层的列表就是根据这个分值进行排序
double score;
//后退指针
struct zskiplistNode *backward;
//层信息描述
struct zskiplistLevel {
//同层中的下一个节点指针
struct zskiplistNode *forward;
//同层中的跨度,用于计数
unsigned long span;
} level[];
} zskiplistNode;
- zskiplist
typedef struct zskiplist {
//分别指向跳跃列表的头结点指针和尾节点指针
struct zskiplistNode *header, *tail;
//列表的长度
unsigned long length;
//列表的高度
int level;
} zskiplist;操作
- 查找过程
/* 查询包含在指定范围内的第一个节点,反之返回null. */
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range)
{
zskiplistNode *x;
int i;
/* 判断传入范围超过列表范围 */
if (!zslIsInRange(zsl, range))
return NULL;
x = zsl->header;
//从最高层向下查找
for (i = zsl->level - 1; i >= 0; i--)
{
/* 在同一层内从左到右依次查找 */
while (x->level[i].forward && !zslValueGteMin(x->level[i].forward->score, range))
x = x->level[i].forward;
}
/* 目标节点不能是最后一个*tail节点 */
x = x->level[0].forward;
serverAssert(x != NULL);
/*再次检测分数限制 */
if (!zslValueLteMax(x->score, range))
return NULL;
return x;
}
先从上到下,再从左到右的进行查找
- 跳跃列表的实际应用
跳跃列表主要是作为zset的一种底层实现,在满足以下三个条件后zset会使用压缩列表-ziplist作为底层实现
- 有序集合元素数量小于128个时
- 元素大小不超过64字节时
- 集合大小操作1G时
如果不同时满足这三个条件时,则使用skipList-跳跃列表作为底层数据结构,这里需要注意的是zset底层结构转换成为skipList以后,就不会在转换成为ziplist
- zset
//如果当前列表长度大于128个时进行转化
if (zzlLength(zobj->ptr)+1 > server.zset_max_ziplist_entries ||
//如果当前列表格式大于64个时进行转化
sdslen(ele) > server.zset_max_ziplist_value ||
//如果当前列表大小大于1G时进行转化
!ziplistSafeToAdd(zobj->ptr, sdslen(ele)))
{
//转换为skip结构
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
} else {
//继续添加数据
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
if (newscore) *newscore = score;
*out_flags |= ZADD_OUT_ADDED;
return 1;
}
}压缩列表
压缩列表本质上是一个字节数组,是redis为了节省内存空间而设计的紧凑性数据结构,可以包含多个元素.压缩列表可以作为有序集合(zset)、散列(hash)、列表(list)
数据结构

- zlbytes:压缩列表的字节长度,占4个字节,因此压缩列表最多有232-1个字节
- zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量,占4个字节
- zllen:压缩列表的元素个数,占2个字节。zllen无法存储元素个数超过65535(216-1)的压缩列表,必须遍历整个压缩列表才能获取到元素个数
- entryX:压缩列表存储的元素,可以是字节数组或者整数,长度不限。entry的编码结构将在后面详细介绍
- zlend:压缩列表的结尾,占1个字节,恒为0xFF
以下是创建ziplist的代码
/* 创建一个空白的ziplist */
unsigned char *ziplistNew(void) {
//ZIPLIST_HEADER_SIZE = (sizeof(uint32_t)*2+sizeof(uint16_t)) + (sizeof(uint8_t))
//8个字节 + 2个字节 + 1个字节
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
//分配内存,返回列表指针
unsigned char *zl = zmalloc(bytes);
//尝试将大端数据转换成小端数据
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
//初始化列表长度
ZIPLIST_LENGTH(zl) = 0;
//设置列表尾部字符为hex_ff
zl[bytes-1] = ZIP_END;
return zl;
}这里需要注意的是第三个步骤使用intrev32ifbe()尝试将大端数据转换成为小段数据;
大小端数据定义
字节的排列方式有两个通用规则。例如,将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序;反之则称大端序。在网络应用中,字节序是一个必须被考虑的因素,因为不同机器类型可能采用不同标准的字节序,所以均按照网络标准转化。
这里redis尽量采用小端的原因是在于X86架构和ARM架构是采用的小端模式,但是网络传输采用的是大端模式.
Entry的内部结构
entry的结构体定义如下:
/* 我们使用这个函数来接收有关 ziplist 条目的信息。
请注意,这不是数据的实际编码方式,这是我们
被一个函数填充以便更容易操作。 */
typedef struct zlentry {
unsigned int prevrawlensize; /* 对prevrawlen编码后的字节大小*/
unsigned int prevrawlen; /* 上一个节点的长度 */
unsigned int lensize; /* 对len编码后的长度*/
unsigned int len; /* 当前节点的长度 */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* 当前节点所使用的编码类型:ZIP_STR_* or ZIP_INT */
unsigned char *p; /* 指向列表第一个元素的指针 */
} zlentry;ziplist中需要注意的是’连锁更新’问题,由于ziplist的结构并不是链表结构而是连续内存结构,导致在删除上一个大节点时会导致数组整体移动的问题
字典
字典又称散列表,是用来存储键值(key-value)对的一种数据结构.
数据结构
Redis字典实现依赖的数据结构主要包含了三部分:字典、Hash表、Hash表节点。字典中嵌入了两个Hash表,Hash表中的table字段存放着Hash表节点,Hash表节点对应存储的是键值对。
结构如下:
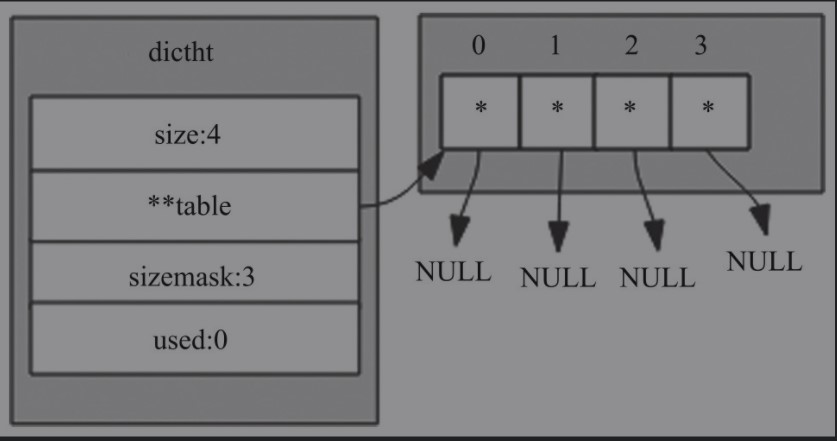
- dict
/*
* hash结构体
* 会同时使用两个hash结构体,以便实现增量扩容
*/
typedef struct dictht {
//指针数组,用于存储键值对
dictEntry **table;
//table数组的大小
unsigned long size;
//掩码(size-1)
unsigned long sizemask;
//已存储的元素数量
unsigned long used;
} dictht;这里着重介绍一下掩码(sizemask)这个字段,sizemask的计算方式为取(size-1)这样的好处是通过
hash_key&sizemask = hash_key/size
位操作的性能要高于取余操作
- dictEntry
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;dictEntry是hash的节点元素结构,需要注意的是V是一种联合体结构,根据使用场景使用不同类型
*next是用来解决hash冲突的,采用的是头插法
- 渐进式ReHash
- 当执行插入\删除\查找\修改时都会先判断当前字典是否在进行rehash,然后尝试进行rehash后才会执行操作
- 线程空闲时会每次对100个节点进行rehash
操作
- 迭代操作
redis中的数据迭代分为两种类型
- 普通迭代器
普通迭代器只会遍历数据 - 安全迭代器
安全迭代器,在遍历过程中会删除数据
这两种迭代器对迭代过程中可能会产生重复数据的处理方式不一样
- 普通迭代器
普通迭代器是通过标志位来限制字典结构的变化 - 安全迭代器
安全迭代器是通过限制rehash来保证数据的准确性
整数集合
redis中的整数集合是作为集合的底层数据结构,用来保存少量的数据和整数元素,下面我们来分析它的数据结构和操作
数据结构
- intset.h
/**
* 整数集合结构体
*/
typedef struct intset {
//编码格式
uint32_t encoding;
//数组长度
uint32_t length;
//元素数组
int8_t contents[];
} intset;可以看到整数集合的结构体比较简单,只有编码格式/长度/数据,这三个部分组成.下面继续分析一下整数数组创建的过程
- intsetNew
/* 创建空白的intset */
intset *intsetNew(void) {
//通过zmalloc分配连续内存
intset *is = zmalloc(sizeof(intset));
//设置编码
is->encoding = intrev32ifbe(INTSET_ENC_INT16);
//设置长度
is->length = 0;
return is;
}操作
操作主要分析添加元素(intsetAdd)和删除元素()这两个操作
- intsetAdd
/* 添加元素 */
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
//1. 计算value的编码格式
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
/*
*判断即将添加的元素是否需要修改intset修改编码才能添加
*/
if (valenc > intrev32ifbe(is->encoding)) {
/* 这个操作默认都是成功的 */
return intsetUpgradeAndAdd(is, value);
} else {
//判断当前元素是否存在于集合中,如果有则返回失败
//*pos
if (intsetSearch(is, value, &pos)) {
if (success) *success = 0;
return is;
}
//判断当前添加元素后是否需要扩容
is = intsetResize(is, intrev32ifbe(is->length) + 1);
//pos如果在当前数组中,需要对元素进行移位操作
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is, pos, pos + 1);
}
//向pos的位置上插入元素value
_intsetSet(is, pos, value);
//设置length
is->length = intrev32ifbe(intrev32ifbe(is->length) + 1);
return is;
}添加元素是通过*pos指针来进行确定位置的,先获取可以插入的位置,在将元素插到指定的位置上,最后在进行位移操作
- intsetRemove
/* 删除元素 */
intset *intsetRemove(intset *is, int64_t value, int *success) {
//判断元素编码
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 0;
//查找元素位置
if (valenc <= intrev32ifbe(is->encoding) && intsetSearch(is, value, &pos)) {
uint32_t len = intrev32ifbe(is->length);
/* We know we can delete */
if (success) *success = 1;
/*使用位移操作覆盖元素*/
if (pos < (len - 1)) intsetMoveTail(is, pos + 1, pos);
//重新设置数组长度
is = intsetResize(is, len - 1);
is->length = intrev32ifbe(len - 1);
}
return is;
}先查找元素,在根据元素的位置进行移位操作.
从intsetAdd方法中可以看到整数集合中的数据是不允许重复的,是有序的数组组成.
quicklist
quicklist是为优化处理List的底层存储结构ziplist和adlist而来,关于List的定义这个描述的比较好
链表是这样一种数据结构,其中的各对象按线性顺序排列。链表与数组的不同点在于,数组的顺序由下标决定,链表的顺序由对象中的指针决定。
关于quicklist的定义如下
Redis中对quciklist的注释为A doubly linked list of ziplists。quicklist是一个双向链表,链表中的每个节点是一个ziplist结构。quicklist可以看成是用双向链表将若干小型的ziplist连接到一起组成的一种数据结构。
数据结构
- quicklist
/**
* quickList结构体
* 大小为40字节
*/
typedef struct quicklist {
//首尾节点
quicklistNode *head;
quicklistNode *tail;
//总条数
unsigned long count;
//节点数量
unsigned long len;
//单个节点的填充因子
int fill : QL_FILL_BITS;
//不同节点的深度
unsigned int compress : QL_COMP_BITS;
unsigned int bookmark_count: QL_BM_BITS;
//书签列表(用于快速查找节点使用)
quicklistBookmark bookmarks[];
} quicklist;对于超大型列表会采用列表尾部使用书签这种数据结构来进行快速查找
- quicklistBookmark
typedef struct quicklistBookmark {
quicklistNode *node;
char *name;
} quicklistBookmark;可以从quicklist/quicklistBookmark的结构体中看到quicklistNode是底层元素存储节点的结构体
- quicklistNode
/**
* quicklistNode 是一个 32 字节的结构,用于描述一个快速列表的ziplist。
* 我们使用sz(位域)将 quicklistNode 保持在 32 字节。
* count: 16位,最大 65536(最大 zl 字节为 65k,因此最大计数实际上 < 32k)。
* encoding: 2位,RAW=1,LZF=2。
* container: 2 位,NONE=1,ZIPLIST=2。
* recompress: 1 位,布尔值,如果节点临时解压缩以供使用,则为 true。
* attempted_compress: 1 位,布尔值,用于测试期间的验证。
* extra: 10 位,免费供以后使用; 填充剩余的 32 位
*/
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;解析quicklistNode:
- 结构上于ziplist不相同,采用的是列表格式记录数据
- 单个node最大链表数量不操作32K
- encoding:LZF进行压缩编码
总结:
redis底层数据格式分为六种
-
简单动态字符串
简单动态字符串(SDS),逻辑上是对*char指针的扩展,结构上根据不同的长度可以分为多种类型,使用惰性删除机制 -
跳跃列表
跳跃列表(skipList)结构上zskiplistNode/zskiplist,zset在满足任意条件(元素个数超过128/元素大小大于64字节/ziplist大小超过1G)后使用skip作为底层数据结构且不会回退 -
压缩列表
压缩列表(ziplist)结构上分为*ziplist/entry,需要注意的是ziplist是连续的内存节点组成,并且entry上还有上一节点的信息 -
字典
字典(dict)结构是通过hash结构来组成,特点是采用位运算与来取余数,并且采用两个hash来实现渐进式Rehash,是通过懒处理和线程空闲时处理的方式来完成 -
整数集合
整数集合结构是连续的内存,每次添加前都要先计算编码长度和插入位置以便进行扩容 -
quicklist
quicklist是一个双向链表结构,每个节点又是ziplist组成 -
stream
省略,详见src/stream.h文件
参考资料
Hacking Strings
zskiplist
redisd源代码的大端与小端
redis压缩列表ziplist的连锁扩容
整数集合

