rocketmq索引实现原理之IndexService
在之前的文章中分析了消息是如果通过Commitlog的逻辑设计到MappedFile的与文件系统进行交付的过程,这篇文章来分析消息体是如何实现快速查找的以及底层实现
RocketMQ的索引相关的工作都是由Store包下的IndexService实现的,IndexService操作的对象是IndexFile,下面主要来分析IndexFile的创建、加载、插入、内容过程。
IndexFile文件的创建过程
创建Index索引文件的过程的触发点是在load()方法中进行触发的,主要是通过IndexService.retryGetAndCreateIndexFile()方法执行的
- IndexService.retryGetAndCreateIndexFile
public IndexFile retryGetAndCreateIndexFile() {
IndexFile indexFile = null;
//1. 重复尝试创建索引文件
for (int times = 0; null == indexFile && times < MAX_TRY_IDX_CREATE; times++) {
//2.获取或创建index文件
indexFile = this.getAndCreateLastIndexFile();
if (null != indexFile)
break;
try {
//线程休眠1s,重新尝试创建indexFile文件
Thread.sleep(1000);
log.info(String.format("Tried to create index file fail. times: %s ,start sleep 1s", times));
} catch (InterruptedException e) {
log.error("Interrupted", e);
}
}
if (null == indexFile) {
this.defaultMessageStore.getAccessRights().makeIndexFileError();
log.error("Mark index file cannot build flag");
}
return indexFile;
}
retryGetAndCreateIndexFile()方法主要是对文件的创建过程有一个重试的机制来尽量保证index文件的成功创建,具体的创建过程就是通过
getAndCreateLastIndexFile()方法来进行创建
- getAndCreateLastIndexFile()
/**
* 获取或创建index文件
*/
private IndexFile getAndCreateLastIndexFile() {
//初始化成员变量
IndexFile indexFile = null;
IndexFile prevIndexFile = null;
long lastUpdateEndPhyOffset = 0;
long lastUpdateIndexTimestamp = 0;
//使用代码块?
{
//执行读锁
this.readWriteLock.readLock().lock();
//如果indexFileList不为空
if (CollectionUtils.isNotEmpty(this.indexFileList)) {
//获取最后一个indexFile
IndexFile tmp = this.indexFileList.get(this.indexFileList.size() - 1);
//判断当前indexFile文件是否写入满额
if (!tmp.isWriteFull()) {
//如果写入满额的法直接使用indexFile
indexFile = tmp;
} else {
//如果写入满额就会查询这个文件的最后一次写入的offset
lastUpdateEndPhyOffset = tmp.getEndPhyOffset();
//查询最后一次更新的时间戳
lastUpdateIndexTimestamp = tmp.getEndTimestamp();
//标记当前文件为上一个使用的索引文件
prevIndexFile = tmp;
}
}
//释放锁操作
this.readWriteLock.readLock().unlock();
}
//indexFile文件没有获取成功时
if (indexFile == null) {
try {
//计算index fileName 格式为yyyyMMddHHmmssSSS
String fileName = this.storeIndexPath + File.separator + UtilAll.timeMillisToHumanString(System.currentTimeMillis());
//新建indexFile文件
indexFile = new IndexFile(fileName, this.hashSlotNum, this.indexNum, lastUpdateEndPhyOffset, lastUpdateIndexTimestamp);
//占用写锁
this.readWriteLock.writeLock().lock();
this.indexFileList.add(indexFile);
} catch (Exception e) {
log.error("getLastIndexFile exception ", e);
} finally {
//释放写锁
this.readWriteLock.writeLock().unlock();
}
if (indexFile != null) {
//对上一个index文件进行刷盘操作
final IndexFile flushThisFile = prevIndexFile;
Thread flushThread = new Thread(() -> this.flush(flushThisFile), "FlushIndexFileThread");
flushThread.setDaemon(true);
flushThread.start();
}
}
return indexFile;
}
getAndCreateLastIndexFile()方法主要是分为三个步骤
- 查询可以使用的indexFile文件
- 如果没有index文件就新建一个indexFile文件
- 尝试将已经满额的indexFile文件刷盘
IndexFile文件的加载过程
IndexService的加载过程是由load()方法实现的,这个方法的被调用链是由
BrokerController -> DefaultMessageStore -> IndexService
load()构造方法主要是对原有的index文件分析然后生成IndexFile对象的过程
- load()
public boolean load(final boolean lastExitOK) {
//1.查找指定文件目录下的文件列表
File dir = new File(this.storeIndexPath);
File[] files = dir.listFiles();
if (files != null) {
//2.按照文件名称进行升序
Arrays.sort(files);
for (File file : files) {
try {
//3.根据index文件初始化indexFile对象
IndexFile f = new IndexFile(file.getPath(), this.hashSlotNum, this.indexNum, 0, 0);
//3.初始化indexFile对象的头文件信息
f.load();
//4.判断上次是否正常退出,未正常退出并且文件记录在日志保存点之后的进行舍弃
if (!lastExitOK && f.getEndTimestamp() > this.defaultMessageStore.getStoreCheckpoint().getIndexMsgTimestamp()) {
//4.1 舍弃未到保存点的数据
f.destroy(0);
continue;
}
log.info("load index file OK, " + f.getFileName());
//5.将文件装载到indexFileList中
this.indexFileList.add(f);
} catch (IOException e | NumberFormatException e) {
//省略...
}
}
}
return true;
}这段代码就是对之前的indexFile文件进行加载,并且对在日志保存点之后的数据进行抛弃。
- IndexFile()
public IndexFile(final String fileName, final int hashSlotNum, final int indexNum,
final long endPhyOffset, final long endTimestamp) throws IOException {
//计算index文件大小 = 头信息长度 + 哈希slot数量*哈希slot长度 + index数量*index长度
int fileTotalSize = IndexHeader.INDEX_HEADER_SIZE + (hashSlotNum * hashSlotSize) + (indexNum * indexSize);
//创建mappedFile对象
this.mappedFile = new MappedFile(fileName, fileTotalSize);
//对属性进行赋值
this.fileChannel = this.mappedFile.getFileChannel();
this.mappedByteBuffer = this.mappedFile.getMappedByteBuffer();
this.hashSlotNum = hashSlotNum;
this.indexNum = indexNum;
//处理文件头信息
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
this.indexHeader = new IndexHeader(byteBuffer);
//初始化'空间位置'和'时间位置'
if (endPhyOffset > 0) {
this.indexHeader.setBeginPhyOffset(endPhyOffset);
this.indexHeader.setEndPhyOffset(endPhyOffset);
}
if (endTimestamp > 0) {
this.indexHeader.setBeginTimestamp(endTimestamp);
this.indexHeader.setEndTimestamp(endTimestamp);
}
}IndexFile()方法会根据文件名称创建一个index文件对象,这个方法中比较有意思的是会根据配置文件解析、创建头文件信息对象IndexHeader而且还是是通过MappedFile对象进行处理的
IndexFile文件的插入过程
IndexService对外提供插入索引的方法是buildIndex,buildIndex()是通过DefaultMessageStore的ReputMessageService来进行触发的
- ReputMessageService
class ReputMessageService extends ServiceThread {
//真正启动索引任务入口
private void doReput() {
//1.判断索引的offset是否小于commitLog中最小的offset
//2.只处理需要进行索引操作的消息
//3.根据消息组装消息后置处理器
//4/5。处理主节点和从节点的差异
}
@Override
public void run() {
while (!this.isStopped()) {
try {
Thread.sleep(1);
this.doReput();
} catch (Exception e) {
}
}
}
}在ReputMessageService可以看到是使用一个循环每隔1s去查询一次commitLog文件中需要进行后置处理的消息来进行处理
IndexFile文件的查询过程
前面介绍了对indexFile文件的创建、加载、写入的过程,接下介绍一下indexFile文件的查询过程
- 调用流程
NettyRemotingServer -> NettyRemotingAbstract -> QueryMessageProcessor -> DefaultMessageStore -> IndexService -> IndexFile以上是调用索引文件的查询过程,从Netty的服务端到IndexFile文件的整体流程,具体的执行方法是IndexFile文件中的selectPhyOffset()
- selectPhyOffset
//计算出indexFile文件中数据的具体物理位置
int keyHash = indexKeyHashMethod(key);
int slotPos = keyHash % this.hashSlotNum;
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
//根据具体的位置进行取数操作
int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);
long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);
long timeDiff = (long) this.mappedByteBuffer.getInt(absIndexPos + 4 + 8);
int prevIndexRead = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8 + 4);IndexFile文件的内容
索引文件是放置在${rootpath}/index目录下的,文件名称按照yyyyMMddhhmmsssss的形式进行生成,默认大小为400MB,由三个部分组成
- header
- slot table
- index linked list
结构如下所示:
|<-- 40 byte -->|<--- 500w --->|<--- 2000w --->|
+---------------+------------------+-------------------+
| header | slot table | index linked list |
+---------------+------------------+-------------------+详细的数据结构如下所示
header结构
+---------------------+--0
| beginTimestampIndex | ----> 第一条消息的保存时间
+---------------------+--8
| endTimestampIndex | ----> 最后一条消息的保存时间
+---------------------+--16
| beginPhyoffsetIndex | ----> 第一条消息的在commitlog中的偏移量
+---------------------+--24
| endPhyoffsetIndex | ----> 最后一条消息的在commitlog中的偏移量
+---------------------+--32
| hashSlotcountIndex | ----> 哈希槽数量,保存添加到本槽列表的最新索引位置
+---------------------+--36
| indexCountIndex | ----> 索引数量,具体索引数据
+---------------------+--40关键代码可以参考IndexHeader的静态成员变量,以下是展示用例
- IndexHeader
public static final int INDEX_HEADER_SIZE = 40;
private static int beginTimestampIndex = 0;
private static int endTimestampIndex = 8;
private static int beginPhyoffsetIndex = 16;
private static int endPhyoffsetIndex = 24;
private static int hashSlotcountIndex = 32;
private static int indexCountIndex = 36;
//插入indexFile文件的开始时间
public void setBeginTimestamp(long beginTimestamp) {
//本地缓存
this.beginTimestamp.set(beginTimestamp);
//指定位置插入时间戳,beginTimestampIndex默认为0
this.byteBuffer.putLong(beginTimestampIndex, beginTimestamp);
}
这里初始化的静态变量会在插入具体的头文件值时进行使用,可以参考setBeginTimestamp方法;
通过vscode的hexdump插件可以看到indexFile文件的内容如下
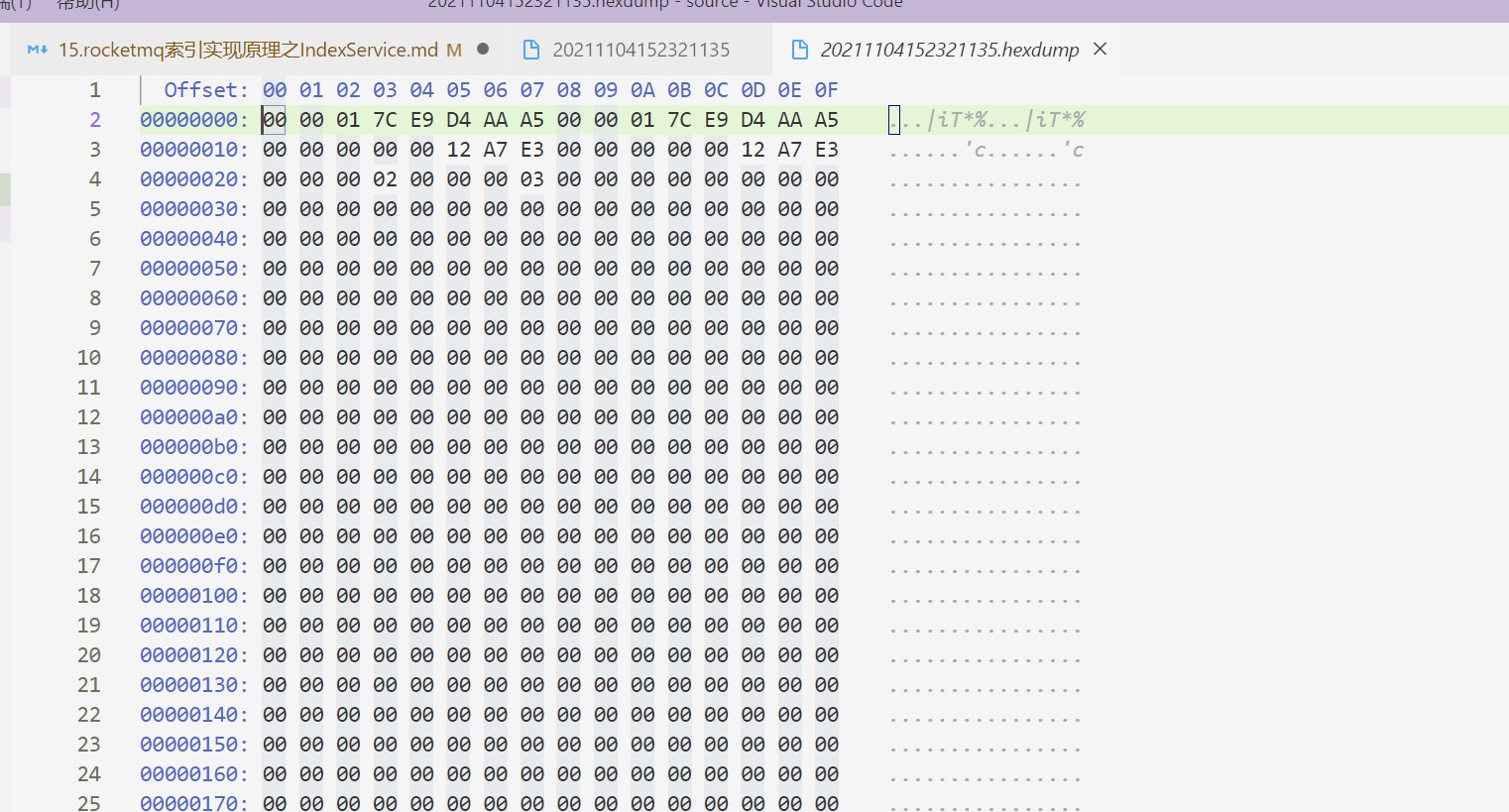
可以看到前8个字节为00 00 01 7C E9 D4 AA A5,通过计算器转换为十进制为1636010601125
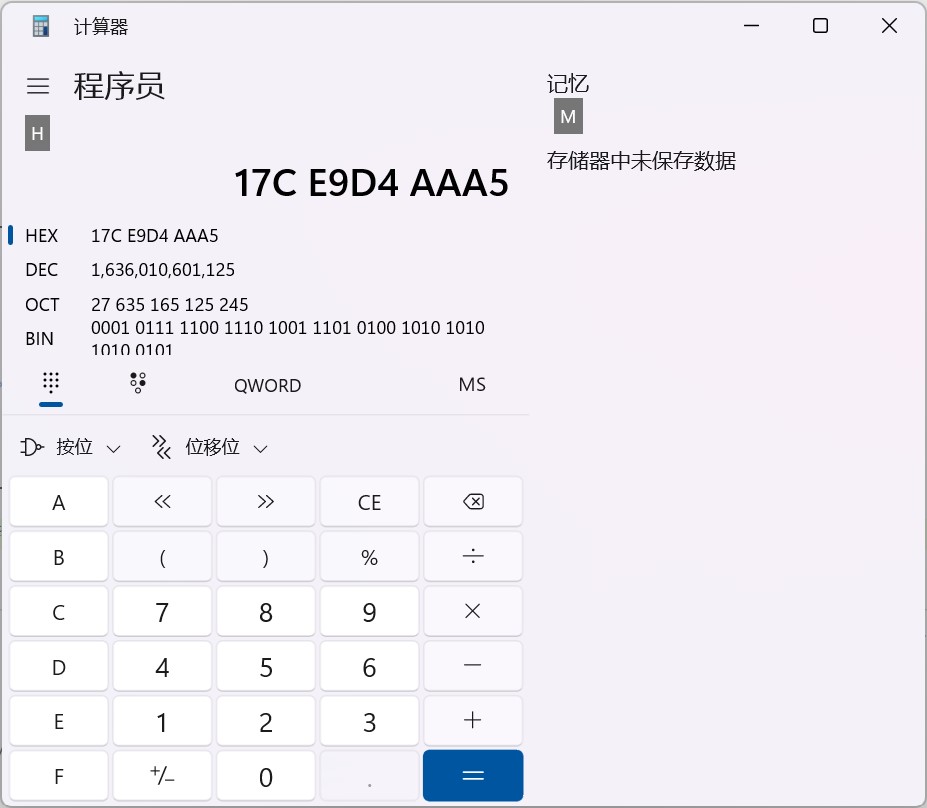
时间戳在进行一次转换可以看到为

剩下的endTimestampIndex、beginPhyoffsetIndex、beginPhyoffsetIndex、endPhyoffsetIndex、hashSlotcountIndex、indexCountIndex信息的处理方式与这个类似,不进行重复了
slot table结构
slot table结构是对
index linked list结构
index linked list的结构是在indexFile上的hash索引之后用存放实际的offset的值
结构如下所示
+---------------------+--0
| key hash | ----> 会根据Topic和key的值拼接在一起计算的一个hash值
+---------------------+--4
| commitLogOffset | ----> commitLog Offset是commitLog文件上的位置
+---------------------+--12
| timeDiff | ----> timeDiff是写入时的相对时间戳
+---------------------+--16
| slotValue | ----> slotValue表示的是记录因为hash冲突造成的下一个节点的数据的相对位置
+---------------------+--20关键的代码如下所示
//1. 写入keyHash 长度为4
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
//2. 写入commitLogOffset 长度为 8
this.mappedByteBuffer.putLong(absIndexPos + 4, commitLogOffset);
//3. 写入时的相对时间戳 长度为 4
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
//4. 写入slotValue 长度为 4,记录因为hash冲突造成的下一个节点的数据的相对位置
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
//5.更新slot上的记录的hash槽位使用数量
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());总结
IndexFile文件最精华的设计在于对索引数据的分类,并且按照分类将数据依次写入IndexFile文件。IndexFile文件分为header、Hash solt、offset三种类型数据

