ShardingSphere入门简介
概览
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。[1]
基本概念
数据分片拆分方式
-
垂直拆分
垂直拆分指的是专库专用,将不同业务的表拆分到对应的库中。微服务架构下已基本实现了垂直拆分。 -
水平拆分
水平拆分指的是逻辑上相同的数据通过根据某种规则将数据分散存储到指定的数据节点中。
产品组成
-
Sharding-JDBC
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。 -
Sharding-Proxy
Sharding-Proxy定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 -
Sharding-Sidecar
Sharding-Sidecar定位为Kubernetes的云原生数据库代理,以Sidecar的形式代理所有对数据库的访问,是想作为DB层面的数据网格。(规划中)
专有名词
| 名称 | 作用 |
|---|---|
| 逻辑表 | 水平拆分的数据库(表)的相同逻辑和数据结构表的总称 |
| 真实表 | 在分片的数据库中真实存在的物理表 |
| 数据节点 | 数据分片的最小单位,由数据源名称和数据表组成(shema.tableName) |
| 绑定表 | 绑定表是shardingSphere中特有的概念,指的是分片规则一致的主表和子表。如果指定互为绑定表,在进行联表查询时将不会出现笛卡尔积 |
| 广播表 | 广播表类似于mycat中的全局表,适用于作为字典 |
| 精确分片算法 | 用于处理使用单一键作为分片键的=与IN进行分片的场景 |
| 范围分片算法 | 用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景 |
| 复合分片算法 | 用于处理使用多键作为分片键进行分片的场景 |
| Hint分片算法 | 用于处理使用Hint行分片的场景(使用外部规则进行分片) |
功能列表
-
数据分片
- 分库 & 分表
- 读写分离
- 分片策略定制化
- 无中心化分布式主键
-
分布式事务
- 标准化事务接口
- XA强一致事务
- 柔性事务
-
数据库治理
- 配置动态化
- 编排 & 治理
- 数据脱敏
- 可视化链路追踪
sharding-jdbc
功能列表
1. 数据分片
2. 读写分离
3. 强制路由
4. 数据脱敏
数据分片配置
server:
port: 8080
tomcat:
uri-encoding: utf-8
spring:
application:
name: shardingsphere-example
jpa:
properties:
hibernate:
enable_lazy_load_no_trans: true
shardingsphere:
datasource:
names: ds0,ds1
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/ds0?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT
username: root
password: 111111
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/ds1?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT
username: root
password: 111111
sharding:
default-database-strategy: # 分库规则
inline:
sharding-column: vender_id
algorithm-expression: ds${vender_id % 2}
tables:
t_user: #t_user表
key-generator-column-name: id #主键
actual-data-nodes: ds${0..1}.t_user${0..1} #真实数据节点
databaseStrategy: # 分库策略
inline:
sharding-column: vender_id # 分库键
algorithm-expression: ds${vender_id % 2}
tableStrategy: #分表策略
inline: #行表达式
shardingColumn: vender_id
algorithmExpression: t_user${vender_id % 2}
sharding: #读写分离配置
master-slave-rules:
ms_ds0:
masterDataSourceName: ds0 # 主库
slaveDataSourceNames:
- ds0_slave0 #从库
- ds0_slave1
loadBalanceAlgorithmType: ROUND_ROBINjdbc不支持的操作
- 不支持存储过程,函数,游标的操作
- 不支持联表删除
DELETE TABLE_XXX1, TABLE_xxx2 FROM TABLE_XXX1 JOIN TABLE_XXX2;
DELETE FROM TABLE_XXX1, TABLE_xxx2 USING TABLE_XXX1 JOIN TABLE_XXX2;- 不建议使用子查询(4.x版本对子查询的优化不太好)
sharding-proxy
功能列表
1. sharding-jdbc提供的功能
2. 权限控制
3. DB高可用管理
数据分片配置
- server.yaml
authentication:
users:
root:
password: 111111
sharding:
password: sharding
authorizedSchemas: sharding_db- config-sharding.yaml
schemaName: sharding_db
dataSources:
ds0:
url: jdbc:mysql://127.0.0.1:3306/ds0?serverTimezone=UTC&useSSL=false
username: root
password: 111111
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds1:
url: jdbc:mysql://127.0.0.1:3306/ds1?serverTimezone=UTC&useSSL=false
username: root
password: 111111
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
t_order:
actualDataNodes: ds${0..1}.t_user
databaseStrategy:
inline:
shardingColumn: vender_id
algorithmExpression: ds${vender_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
defaultDatabaseStrategy:
inline:
shardingColumn: id
algorithmExpression: ds${id % 2}
defaultTableStrategy:
none:注意事项
- 在部署sharding-proxy时需要将mysql driver在lib下
- 不建议使用子查询(4.x版本对子查询的优化不太好)
- 配置文件请以官网为准(5.x版本与4.x版本改动较大)
client与proxy对比
功能对比
| / | Sharding-JDBC | Sharding-Proxy |
|---|---|---|
| 数据库连接 | 任意 | MySql |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
性能对比
Sharding-JDBC与Sharding-Proxy保持相同的数据库、数据库连接配置、后端应用下进行测试
-
单表插入
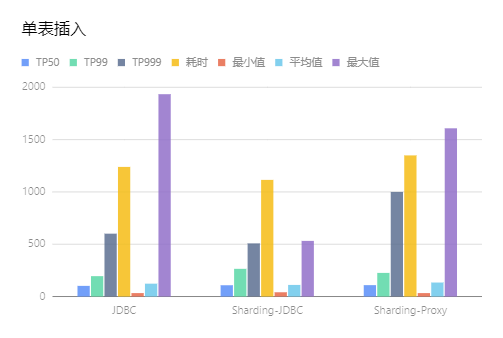
-
单表查询
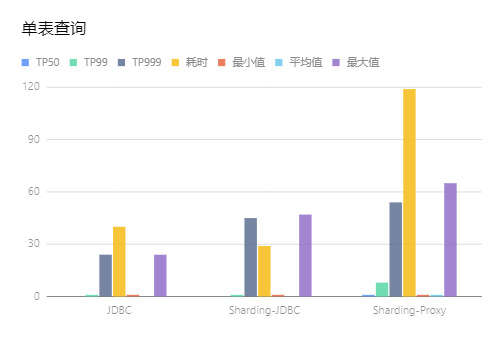
-
结论
从耗时上比较单表插入的性能从高到低依次是Sharding-JDBC、JDBC、Sharding-Proxy
从耗时上比较单表查询的性能从高到低依次是Sharding-JDBC、JDBC、Sharding-Proxy
扩展部分
源码分析
- Sharding-JDBC的数据分片的执行过程

ShardingRouter.route()方法作为路由的核心,主要是返回路由对象SQLRouteResult,SQLRouteResult保存路由信息
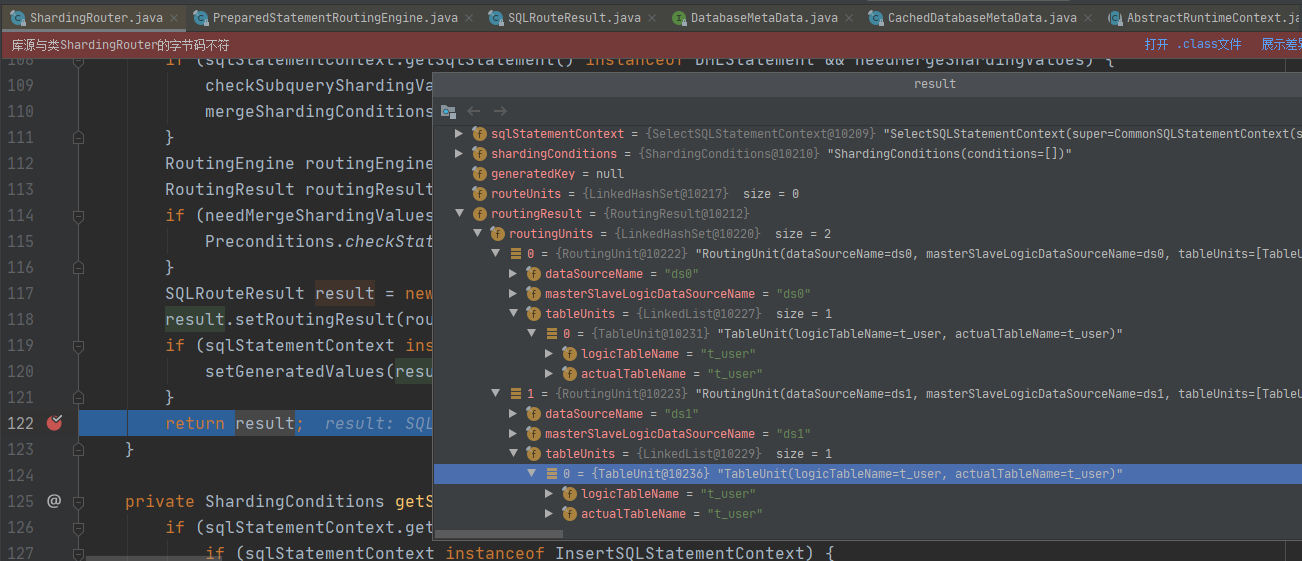
RouteResult对象会被返回到ShardingPreparedStatement中,这个类继承于java.sql.Statement,Statement是定义数据库进行交互并返回结果的接口
- ShardingPreparedStatement扩展的方法
public ShardingPreparedStatement extends AbstractShardingPreparedStatementAdapter {
//分片连接
@Getter
private final ShardingConnection connection;
//执行sql
private final String sql;
//分片引擎
private final PreparedQueryShardingEngine shardingEngine;
//执行器
private final PreparedStatementExecutor preparedStatementExecutor;
//批处理执行器
private final BatchPreparedStatementExecutor batchPreparedStatementExecutor;
//sql路由器
private SQLRouteResult sqlRouteResult;
//结果集
private ResultSet currentResultSet;
//实现executeQuery、executeUpdate、execute、getGeneratedKeys等方法
}
execute()方法进行具体的执行过程
public boolean execute() throws SQLException {
try {
//清除环境
clearPrevious();
//进行分片环境设置
shard();
//初始化预处理执行器
initPreparedStatementExecutor();
//执行
return preparedStatementExecutor.execute();
} finally {
clearBatch();
}
}- initPreparedStatementExecutor()方法初始化预处理执行
private void initPreparedStatementExecutor() throws SQLException {
//初始化执行器
preparedStatementExecutor.init(sqlRouteResult);
//设置语句参数
setParametersForStatements();
replayMethodForStatements();
}**preparedStatementExecutor.execute()**方法是具体执行的方法
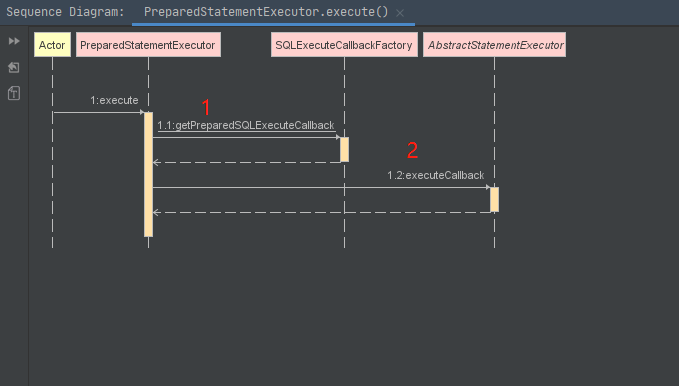
1处将待执行sql封装成为回调对象,2处**executeCallback(executeCallback)**执行回调对象
- executeCallback在回调中执行sql
@Override
protected Boolean executeSQL(final String sql, final Statement statement, final ConnectionMode connectionMode) throws SQLException {
return ((PreparedStatement) statement).execute();
}
- executeCallback()
List<T> result = sqlExecuteTemplate.executeGroup((Collection) executeGroups, executeCallback);
refreshMetaDataIfNeeded(connection.getRuntimeContext(), sqlStatementContext);
return result;通过sqlExecuteTemplate.executeGroup执行方法,会将执行动作传递到执行引擎ShardingExecuteEngine的groupExecute方法
public <I, O> List<O> groupExecute(
final Collection<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> firstCallback, final ShardingGroupExecuteCallback<I, O> callback, final boolean serial)
throws SQLException {
if (inputGroups.isEmpty()) {
return Collections.emptyList();
}
return serial ? serialExecute(inputGroups, firstCallback, callback) : parallelExecute(inputGroups, firstCallback, callback);
}在这里同步执行方法和异步执行方法,并且将第一个任务交给当前线程进行处理
private <I, O> List<O> parallelExecute(final Collection<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> firstCallback,
final ShardingGroupExecuteCallback<I, O> callback) throws SQLException {
Iterator<ShardingExecuteGroup<I>> inputGroupsIterator = inputGroups.iterator();
ShardingExecuteGroup<I> firstInputs = inputGroupsIterator.next();
Collection<ListenableFuture<Collection<O>>> restResultFutures = asyncGroupExecute(Lists.newArrayList(inputGroupsIterator), callback);
//如果firstCallback有值就让当前线程进行执行,如果没值就返回线程池执行结果
return getGroupResults(syncGroupExecute(firstInputs, null == firstCallback ? callback : firstCallback), restResultFutures);
}这段代码很细心,不但使用到了当前线程来执行第一个任务,并且线程池也使用的是Guava提供的可回调的线程池ListeningExecutorService,可参考Guava的使用
在执行sql时候又会回到当初创建回调函数的地方进行执行回调方法。

