深入学习Java线程池
转载自:
原文链接: stackify 翻译: ImportNew.com - 一杯哈希不加盐
译文链接: http://www.importnew.com/29212.html导语
线程池是多线程编程中的核心概念,简单来说就是一组可以执行任务的空闲线程。
首先,我们了解一下多线程框架模型,明白为什么需要线程池。
线程是在一个进程中可以执行一系列指令的执行环境,或称运行程序。多线程编程指的是用多个线程并行执行多个任务。当然,JVM 对多线程有良好的支持。
PS:进程可以简单的理解为程序,线程可以理解为进程下实际做事的小兵甲乙丙丁
尽管这带来了诸多优势,首当其冲的就是程序性能提高,但多线程编程也有缺点 —— 增加了代码复杂度、同步问题、非预期结果和增加创建线程的开销。
在这篇文章中,我们来了解一下如何使用 Java 线程池来缓解这些问题。
java线程池
Java 通过 executor 对象来实现自己的线程池模型。可以使用 executor 接口或其他线程池的实现,它们都允许细粒度的控制。
java.util.concurrent 包中有以下接口:
- Executor —— 执行任务的简单接口
- ExecutorService —— 一个较复杂的接口,包含额外方法来管理任务和 executor 本身
- ScheduledExecutorService —— 扩展自 ExecutorService,增加了执行任务的调度方法
除了这些接口,这个包中也提供了 Executors 类直接获取实现了这些接口的 executor 实例。一般来说,一个Java线程池包含以下部分:
- 工作线程的池子,负责管理线程
- 线程工厂,负责创建新线程
- 等待执行的任务队列
在下面的章节,让我们仔细看一看Java类和接口如何为线程池提供支持。
Executors 类和 Executor 接口
Executors 类包含工厂方法创建不同类型的线程池,Executor是个简单的线程池接口,只有一个execute() 方法。
我们通过一个例子来结合使用这两个类(接口),首先创建一个单线程的线程池,然后用它执行一个简单的语句:
Executor executor = Executors.newSingleThreadExecutor();
executor.execute(() -> System.out.println("Single thread pool test"));注意语句写成了lambda表达式,会被自动推断成Runnable类型。
如果有工作线程可用,execute() 方法将执行语句,否则就把Runnable任务放进队列,等待线程可用。
基本上,executor 代替了显式创建和管理线程。
Executors 类里的工厂方法可以创建很多类型的线程池:
- newSingleThreadExecutor():包含单个线程和无界队列的线程池,同一时间只能执行一个任务
- newFixedThreadPool():包含固定数量线程并共享无界队列的线程池;当所有线程处于工作状态,有新任务提交时,任务在队列中等待,直到一个线程变为可用状态
- newCachedThreadPool():只有需要时创建新线程的线程池
- newWorkStealingThreadPool():基于工作窃取(work-stealing)算法的线程池,后面章节详细说明
ps:**newWorkStealingThreadPool()**的源代码是这样的
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}Runtime.getRuntime().availableProcessors()返回的是机器的逻辑处理器数量
默认的newWorkStealingPool会返回一个期望并行度为当前逻辑处理器数量的Fork/Join线程池
接下来,让我们看一下 ExecutorService 接口提供了哪些新功能?
- ExecutorService
创建 ExecutorService 方式之一便是通过 Excutors 类的工厂方法
ExecutorService executor = Executors.newFixedThreadPool(10);
除了execute()方法,接口也定义了相似的submit()方法,这个方法可以返回一个Future对象。
ExecutorService executor = Executors.newWorkStealingPool();
Callable<Double> callableTask = () -> {
//业务操作
return 0.02d;
};
Future<Double> future = executor.submit(callableTask);
// 判断是否执行完毕
if (future.isDone()) {
double result = future.get();
}从上面的例子可以看到Future接口可以返回Callable类型任务的结果,而且能显示任务的执行状态。
当没有任务等待执行时,ExecutorService并不会自动销毁,所以你可以使用shutdown()或shutdownNow()来显式关闭它。
executor.shutdown();
ScheduledExecutorService
这是ExecutorService的一个子接口,增加了调度任务的方法
ScheduledExecutorService executor = Executors.newScheduledThreadPool(10);
schedule() 方法的参数指定执行的方法、延时和 TimeUnit
Future
future = executor.schedule(callableTask, 2, TimeUnit.MILLISECONDS);
另外,这个接口定义了其他两个方法:
xecutor.scheduleAtFixedRate(
() -> System.out.println("Fixed Rate Scheduled"), 2, 2000, TimeUnit.MILLISECONDS);
executor.scheduleWithFixedDelay(
() -> System.out.println("Fixed Delay Scheduled"), 2, 2000, TimeUnit.MILLISECONDS);scheduleAtFixedRate() 方法延时 2 毫秒执行任务,然后每 2 秒重复一次。相似的,scheduleWithFixedDelay() 方法延时 2毫秒后执行第一次,然后在上一次执行完成 2 秒后再次重复执行。
在下面的章节,我们来看一下 ExecutorService 接口的两个实现:ThreadPoolExecutor 和ForkJoinPool。
ps:ScheduledExecutorService具有延迟功能的线程池
ThreadPoolExecutor
这个线程池的实现增加了配置参数的能力。创建 ThreadPoolExecutor 对象最方便的方式就是通过Executors 工厂方法:
ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(10);
这种情况下,线程池按照默认值预配置了参数。线程数量由以下参数控制:
- corePoolSize 和 maximumPoolSize:表示线程数量的范围
- keepAliveTime:决定了额外线程存活时间
我们深入了解一下这些参数如何使用。
当一个任务被提交时,如果执行中的线程数量小于 corePoolSize,一个新的线程被创建。如果运行的线程数量大于 corePoolSize,但小于 maximumPoolSize,并且任务队列已满时,依然会创建新的线程。如果多于 corePoolSize 的线程空闲时间超过 keepAliveTime,它们会被终止。
上面那个例子中,newFixedThreadPool() 方法创建的线程池,corePoolSize=maximumPoolSize=10 并且 keepAliveTime 为 0 秒。
如果你使用 newCachedThreadPool() 方法,创建的线程池 maximumPoolSize 为Integer.MAX_VALUE,并且 keepAliveTime 为 60 秒。
ThreadPoolExecutor cachedPoolExecutor = (ThreadPoolExecutor) Executors.newCachedThreadPool();
The parameters can also be set through a constructor or through setter methods:
这些参数也可以通过构造函数或setter方法设置:
ThreadPoolExecutor executor = new ThreadPoolExecutor(24, 6, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>());
executor.setMaximumPoolSize(8);ThreadPoolExecutor 的一个子类便是 ScheduledThreadPoolExecutor,它实现了ScheduledExecutorService 接口。你可以通过 newScheduledThreadPool() 工厂方法来创建这种类型的线程池。
ScheduledThreadPoolExecutor executor = (ScheduledThreadPoolExecutor) Executors.newScheduledThreadPool(5);
上面语句创建了一个线程池,corePoolSize 为 5,maximumPoolSize 无限制,keepAliveTime 为 0 秒。
ForkJoinPool
另一个线程池的实现是 ForkJoinPool 类。它实现了 ExecutorService 接口,并且是 Java 7 中 fork/join 框架的重要组件。
fork/join 框架基于“工作窃取算法”。简而言之,意思就是执行完任务的线程可以从其他运行中的线程“窃取”工作。
ForkJoinPool 适用于任务创建子任务的情况,或者外部客户端创建大量小任务到线程池。
这种线程池的工作流程如下:
- 创建 ForkJoinTask 子类
- 根据某种条件将任务切分成子任务
- 调用执行任务
- 将任务结果合并
- 实例化对象并添加到池中
创建一个ForkJoinTask,你可以选择RecursiveAction或RecursiveTask这两个子类,后者有返回值。
我们来实现一个继承RecursiveTask的类,计算阶乘,并把任务根据阈值划分成子任务。
public class FactorialTask extends RecursiveTask<BigInteger> {
private int start = 1;
private int n;
private static final int THRESHOLD = 20;
// standard constructors
@Override
protected BigInteger compute() {
if ((n - start) >= THRESHOLD) {
return ForkJoinTask.invokeAll(createSubtasks())
.stream()
.map(ForkJoinTask::join)
.reduce(BigInteger.ONE, BigInteger::multiply);
} else {
return calculate(start, n);
}
}
}这个类需要实现的主要方法就是重写 compute() 方法,用于合并每个子任务的结果。
具体划分任务逻辑在 createSubtasks() 方法中:
private Collection<FactorialTask> createSubtasks() {
List<FactorialTask> dividedTasks = new ArrayList<>();
int mid = (start + n) / 2;
dividedTasks.add(new FactorialTask(start, mid));
dividedTasks.add(new FactorialTask(mid + 1, n));
return dividedTasks;
}最后,calculate() 方法包含一定范围内的乘数。
private BigInteger calculate(int start, int n) {
return IntStream.rangeClosed(start, n)
.mapToObj(BigInteger::valueOf)
.reduce(BigInteger.ONE, BigInteger::multiply);
}接下来,任务可以添加到线程池:
ForkJoinPool pool = ForkJoinPool.commonPool();
BigInteger result = pool.invoke(new FactorialTask(100));ThreadPoolExecutor 与 ForkJoinPool 对比
初看上去,似乎 fork/join 框架带来性能提升。但是这取决于你所解决问题的类型。
当选择线程池时,非常重要的一点是牢记创建、管理线程以及线程间切换执行会带来的开销。
-
ThreadPoolExecutor可以控制线程数量和每个线程执行的任务,这很适合你需要在不同的线程上执行少量巨大的任务
-
相比较而言,ForkJoinPool 基于线程从其他线程“窃取”任务。正因如此,当任务可以分割成小任务时可以提高效率。
为了实现工作窃取算法,fork/join 框架使用两种队列:
- 包含所有任务的主要队列
- 每个线程的任务队列
当线程执行完自己任务队列中的任务,它们试图从其他队列获取任务。为了使这一过程更加高效,线程任务队列使用双端队列(double ended queue)数据结构,一端与线程交互,另一端用于“窃取”任务。来自The H Developer的图很好的表现出了这一过程:
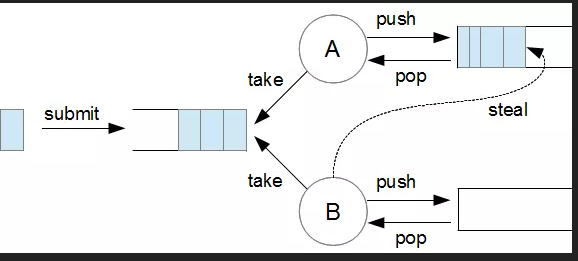
和这种模型相比,ThreadPoolExecutor 只使用一个主要队列。
最后要注意的一点 ForkJoinPool 只适用于任务可以创建子任务。否则它和 ThreadPoolExecutor没区别,甚至开销更大。
ps:每个工作线程都维持着一个双端的任务队列,当一个工作线程执行完成对应工作队列中的任务时,会去其他线程对应的任务队列尾端去获取待执行的任务来进行执行。
总结
线程池有很大优势,简单来说就是可以将任务的执行从线程的创建和管理中分离。另外,如果使用得当,它们可以极大提高应用的性能。
如果你学会充分利用线程池,Java 生态系统好处便是其中有很多成熟稳定的线程池实现。
收藏笔记
展示了由Executors提供的几种常用的线程池:
- ScheduledExecutorService
- ThreadPoolExecutor
- ForkJoinPool
前两种都是基于ThreadPoolExecutor的封装,最后一种是基于ForkJoinPool的封装。
ThreadPoolExecutor适合于执行少量耗时的任务,线程数可估。
ForkJoinPool适合于可分解的任务
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}RecursiveTask 提交任务时如果提交线程是ForkJoinWorkerThread就向线程所属于的任务队列进行提交;
如果不是就说明是业务线程第一次向ForkJoinThreadPool提交任务,就调用ForkJoinPool的通用线程池进行任务的提交
- 初始化ForkJoinPool.common

4个逻辑处理器-1,得到forkJoin的并行度为3
CPU逻辑核数(CPU线程数,Thread):通过超线程技术,能将一个物理核分成多个逻辑核
一般情况,一颗物理CPU可以有多个物理内核,加上intel的超线程技术(HT, Hyper-Threading)能够把一个物理处理器(核心,内核)在软件层变成两个逻辑处理器,可以使处理器在某一时刻,同步并行处理更多指令和数据(即有多个线程并行工作)。
逻辑核心数指的就是线程数

