sharding-jdbc的查询过程分析
上一章简单的说了一下sharding-jdbc的使用方法,这一章分析一下sharding-jdbc进行数据分片的原理
概念
数据分片指的是数据按照某个维度将单一数据库的数据分散到多个数据库或多个数据表中达到已提升性能瓶颈已经可用性的效果。数据分片主要分为水平分片、垂直分片。
水平分片
水平分片指的是根据某种规则将数据分散到多个库或多个表中,每个分片包含数据的一部分
垂直分片
垂直分片指的是按照业务来进行划分专库专用,每个表都放到专门的库中
内核剖析
- 核心流程
SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并
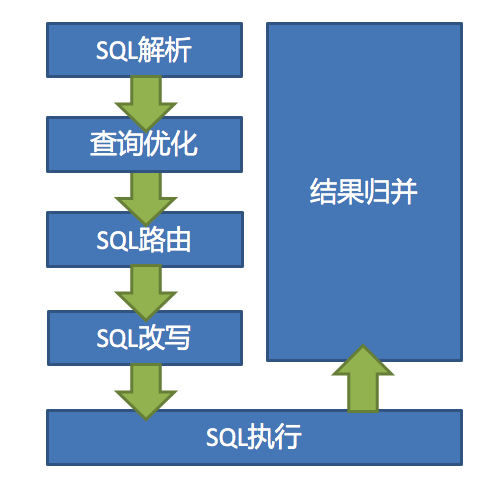
- SQL解析主要是通过sql解析器对sql进行理解
- 执行器优化主要是合并和优化分片条件
- SQL路由根据路由策略生成路由路径
- SQL改写将sql改写为真实数据库可以执行的语句
- SQL执行通过多线程异步执行
- 结果并归将多个结果集进行合并返回
代码分析
ShardingRouter核心分析
ShardingRouter.route()方法作为路由的核心,主要是返回路由对象SQLRouteResult,这个对象保存路由信息。
RouteResult对象最终被返回到ShardingPreparedStatement。这个类继承于java.sql.Statement,Statement定义了与数据库进行交互并返回结果的接口。
- ShardingPreparedStatement
public ShardingPreparedStatement extends AbstractShardingPreparedStatementAdapter {
//分片连接
@Getter
private final ShardingConnection connection;
//执行sql
private final String sql;
//分片引擎
private final PreparedQueryShardingEngine shardingEngine;
//执行器
private final PreparedStatementExecutor preparedStatementExecutor;
//批处理执行器
private final BatchPreparedStatementExecutor batchPreparedStatementExecutor;
//sql路由器
private SQLRouteResult sqlRouteResult;
//结果集
private ResultSet currentResultSet;
//实现executeQuery、executeUpdate、execute、getGeneratedKeys等方法
}
execute()方法
public boolean execute() throws SQLException {
try {
//清除环境
clearPrevious();
//进行分片环境设置
shard();
//初始化预处理执行器
initPreparedStatementExecutor();
//执行
return preparedStatementExecutor.execute();
} finally {
clearBatch();
}
}shard()方法已经在上面进行了分析,我们继续分析一下initPreparedStatementExecutor方法
- initPreparedStatementExecutor
private void initPreparedStatementExecutor() throws SQLException {
//初始化执行器
preparedStatementExecutor.init(sqlRouteResult);
//设置语句参数
setParametersForStatements();
replayMethodForStatements();
}**preparedStatementExecutor.execute()**方法是具体执行的方法
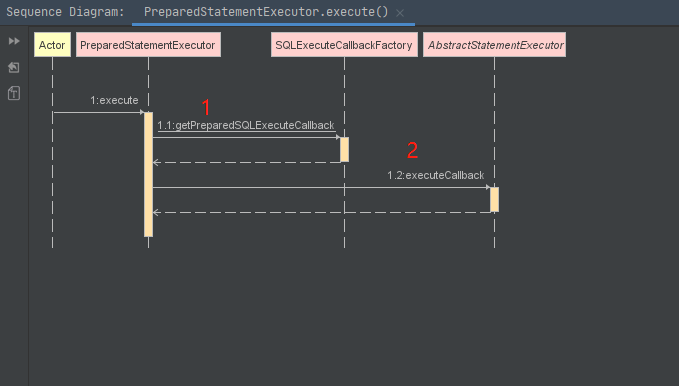
1处将待执行sql封装成为回调对象,2处**executeCallback(executeCallback)**执行回调对象
- executeCallback在回调中执行sql
@Override
protected Boolean executeSQL(final String sql, final Statement statement, final ConnectionMode connectionMode) throws SQLException {
return ((PreparedStatement) statement).execute();
}
- executeCallback()
List<T> result = sqlExecuteTemplate.executeGroup((Collection) executeGroups, executeCallback);
refreshMetaDataIfNeeded(connection.getRuntimeContext(), sqlStatementContext);
return result;通过sqlExecuteTemplate.executeGroup执行方法,会将执行动作传递到执行引擎ShardingExecuteEngine的groupExecute方法
public <I, O> List<O> groupExecute(
final Collection<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> firstCallback, final ShardingGroupExecuteCallback<I, O> callback, final boolean serial)
throws SQLException {
if (inputGroups.isEmpty()) {
return Collections.emptyList();
}
return serial ? serialExecute(inputGroups, firstCallback, callback) : parallelExecute(inputGroups, firstCallback, callback);
}在这里同步执行方法和异步执行方法,并且将第一个任务交给当前线程进行处理
private <I, O> List<O> parallelExecute(final Collection<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> firstCallback,
final ShardingGroupExecuteCallback<I, O> callback) throws SQLException {
Iterator<ShardingExecuteGroup<I>> inputGroupsIterator = inputGroups.iterator();
ShardingExecuteGroup<I> firstInputs = inputGroupsIterator.next();
Collection<ListenableFuture<Collection<O>>> restResultFutures = asyncGroupExecute(Lists.newArrayList(inputGroupsIterator), callback);
//如果firstCallback有值就让当前线程进行执行,如果没值就返回线程池执行结果
return getGroupResults(syncGroupExecute(firstInputs, null == firstCallback ? callback : firstCallback), restResultFutures);
}这段代码很细心,不但使用到了当前线程来执行第一个任务,并且线程池也使用的是Guava提供的可回调的线程池ListeningExecutorService,可参考Guava的使用
在执行sql时候又会回到当初创建回调函数的地方进行执行回调方法。
总结:
sharding-jdbc在执行sql的时候首先要获取分库的配置生成statement,然后构造回调函数,将回调函数放到线程池中去执行得到结果并执行回调函数合并结果返回,接下来重点介绍一下sharding-jdbc的详细用法。

