sharding-jdbc分库分表实践
在项目中大量的使用到sharding-jdbc,今天将它的实践用法做一个总结。
总结前先提几个问题:
- 为什么要用sharding-jdbc?
- 如何使用?
- 有什么注意事项?
- 同类型的框架对比?
让我们带着问题去开始了解sharding-jdbc。
基础知识
sharding-jdbc是定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- roadmap
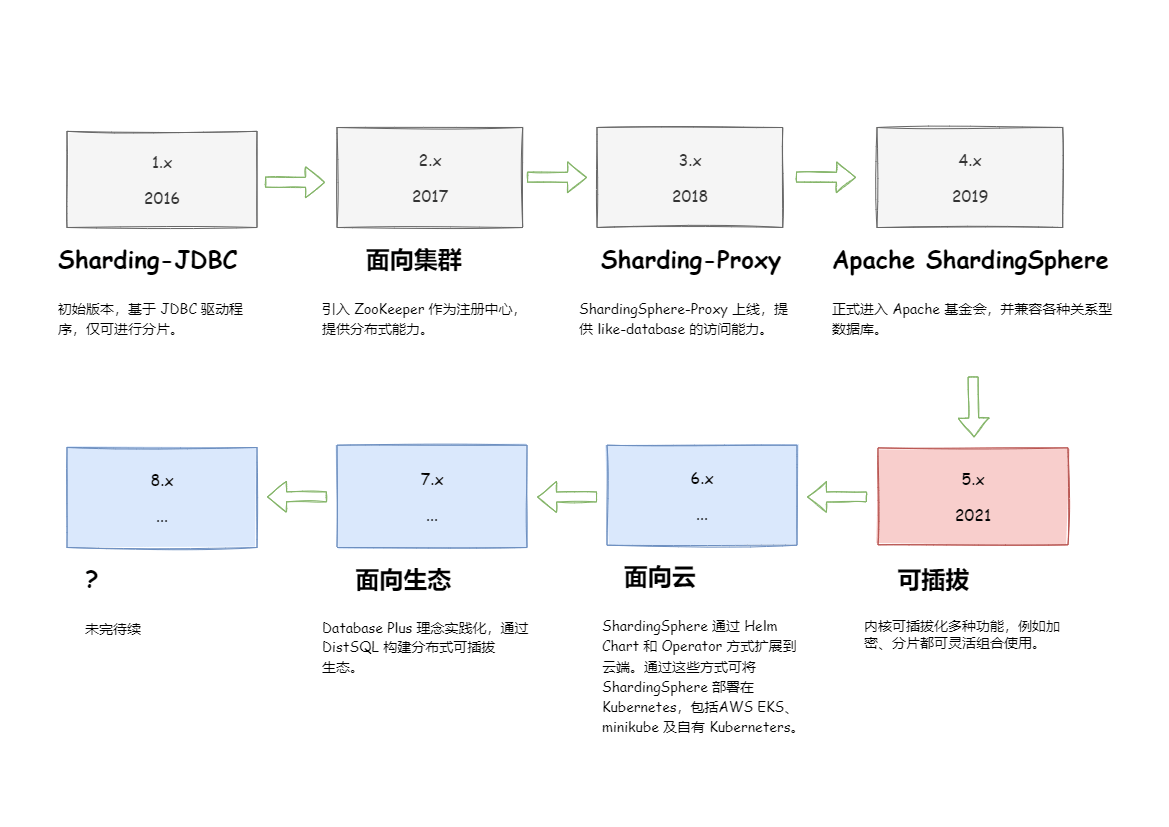
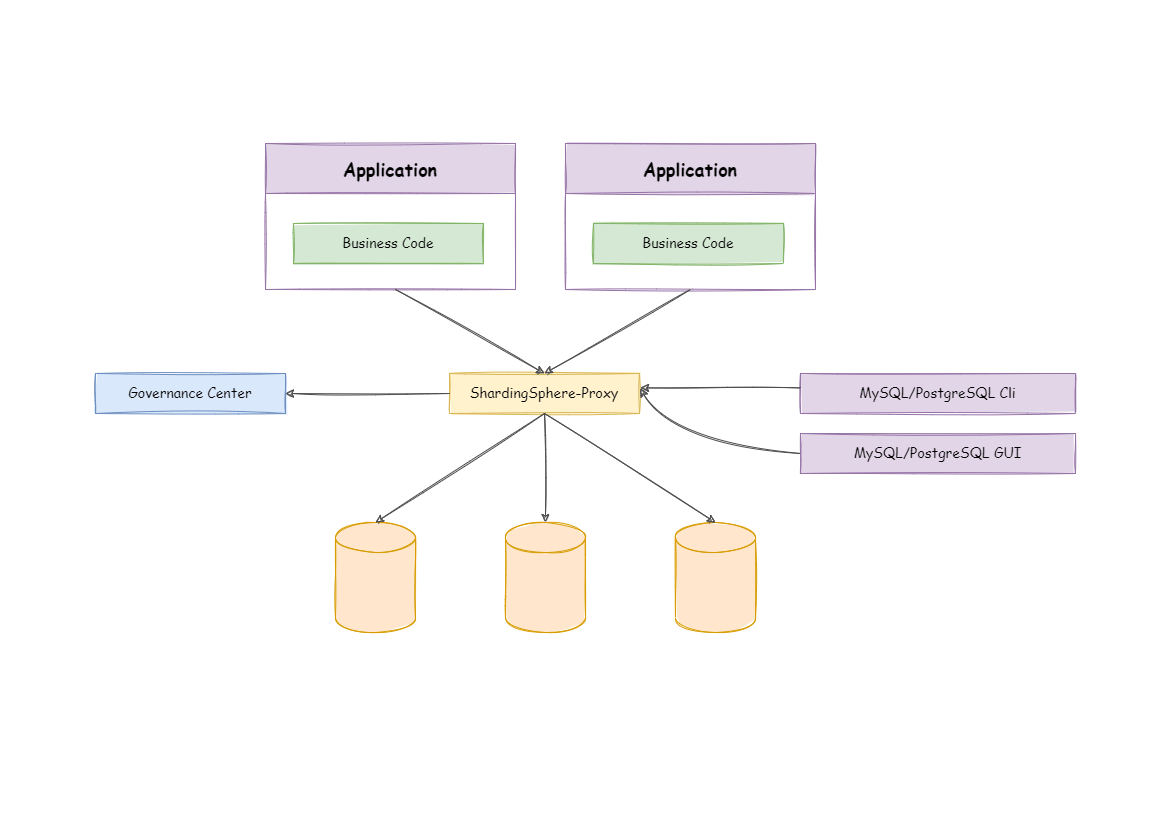
- Sharding-Proxy
- 支持的功能

快速入门
maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>${latest.release.version}</version>
</dependency>规则配置
Sharding-JDBC可以通过Java,YAML,Spring命名空间和Spring Boot Starter四种方式配置,开发者可根据场景选择适合的配置方式。详情请参见配置手册。
创建DataSource
通过ShardingDataSourceFactory工厂和规则配置对象获取ShardingDataSource,ShardingDataSource实现自JDBC的标准接口DataSource。然后即可通过DataSource选择使用原生JDBC开发,或者使用JPA, MyBatis等ORM工具。
演示实例
- 用springBoot Starter+mysql方式演示
- pom文件
<properties>
<sharding.jdbc.version>4.0.1</sharding.jdbc.version>
</properties>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding.jdbc.version}</version>
</dependency>
<!-- for spring namespace -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>${sharding.jdbc.version}</version>
</dependency>- 分库分表配置规则(基于yml文件)
spring:
shardingsphere:
datasource:
names: ds0,ds1
# 数据源ds0
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/ds0?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT
username: root
password: 111111
# 数据源ds1
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/ds1?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT
username: root
password: 111111
sharding:
default-database-strategy: # 分库规则
inline:
sharding-column: vender_id
algorithm-expression: ds${vender_id % 2}
tables:
t_user: #t_user表
key-generator-column-name: id #主键
actual-data-nodes: ds${0..1}.t_user #真实数据节点
database-strategy: # 分库策略
inline:
sharding-column: vender_id # 分库键
algorithm-expression: ds${vender_id % 2}
# tableStrategy: #分表策略
# inline: #行表达式
# shardingColumn: vender_id
# algorithmExpression: t_user${vender_id % 2}- 创建DataSource
由于引入使用了SpringBoot Mybatis因此会自动装配相应的DataSource
<!-- SpringBoot Mybatis 依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>如果在不同的库中有相同的表,但是未设置分库策略的话会随机使用一个连接进行查询(这一点可以在下一章中分析原因)
注意事项
sharding-jdbc官网上的示例地址已经不是跳转的那个单独的演示项目地址了,已经被合并到主项目中。直接下载主项目时候如果是window会提示文件名称太长,官网已经给了解决方案
git config --global core.longpaths true总结
以上只是粗略的将sharding-jdbc介绍了一下,下一篇文章我们来分析一下sharding-jdbc的原理。
- 参考资料

