Consumer源代码分析
消费流程
DefaultMQPushConsumer
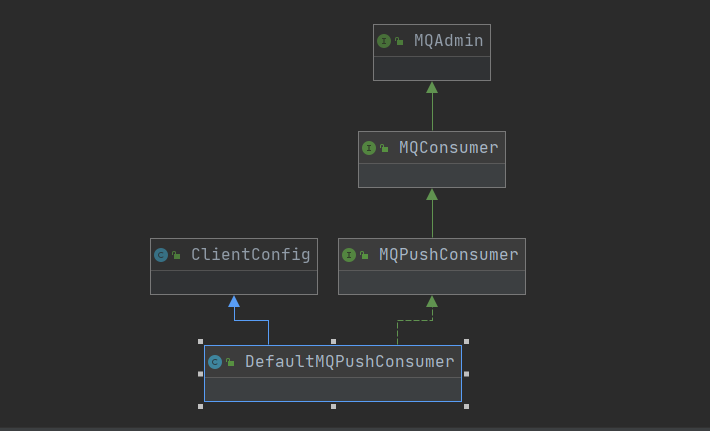
DefaultMQPushConsumer是默认进行消费的工具类,类图如下:
public DefaultMQPushConsumer(final String namespace, final String consumerGroup, RPCHook rpcHook,
AllocateMessageQueueStrategy allocateMessageQueueStrategy) {
this.consumerGroup = consumerGroup;
this.namespace = namespace;
this.allocateMessageQueueStrategy = allocateMessageQueueStrategy;
defaultMQPushConsumerImpl = new DefaultMQPushConsumerImpl(this, rpcHook);
}默认的构造函数参数如下
| 参数 | 含义 |
|---|---|
| namespace | 指定producer/consumer实例,只有在同一个实例下的消息才能被消费到 |
| consumerGroup | 消费组 |
| defaultMQPushConsumerImpl | |
| allocateMessageQueueStrategy | 默认的消费策略 |
| namesrvAddr | namesrv的地址 |
| subscribe(topic,subExpression) | 订阅的主题和tag过滤的规则 |
实现原理
主要是一下几个步骤
- 准备环境,设置各种环境变量(例如topic,过滤策略),根据环境变量初始化pullRequest
- 从本地或者Broker中获取到offerSet偏移量
- 从本地的brokerTable中获取到对应的broker地址
- 调用MQClientAPIImpl操作获取消息并执行回调(将Netty的操作封装成MQ层面的业务操作)
- 底层调用NettyRemotingClient进行网络连接,特殊的报文结构
消息的方式是通过“长轮询”的方式进行处理的,通过服务端hold住请求(默认是15s)来实现的
源代码分析
ConsumerMessageConcurrentlyService
上面讲到如何初始化一个DefaultMQPushConsumer,但是在实际执行获取动作的是ConsumerMessageConcurrentlyService来进行的。
public ConsumeMessageConcurrentlyService(DefaultMQPushConsumerImpl defaultMQPushConsumerImpl,
MessageListenerConcurrently messageListener) {
this.defaultMQPushConsumerImpl = defaultMQPushConsumerImpl;
this.messageListener = messageListener;
this.defaultMQPushConsumer = this.defaultMQPushConsumerImpl.getDefaultMQPushConsumer();
this.consumerGroup = this.defaultMQPushConsumer.getConsumerGroup();
this.consumeRequestQueue = new LinkedBlockingQueue<Runnable>();
//1. 创建一个主线程池用来拉去消息
this.consumeExecutor = new ThreadPoolExecutor(
this.defaultMQPushConsumer.getConsumeThreadMin(),
this.defaultMQPushConsumer.getConsumeThreadMax(),
1000 * 60,
TimeUnit.MILLISECONDS,
this.consumeRequestQueue,
new ThreadFactoryImpl("ConsumeMessageThread_"));
//2. 创建一个用来执行推迟消费的线程池
this.scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(new ThreadFactoryImpl("ConsumeMessageScheduledThread_"));
//3. 定时清理超时的消息
this.cleanExpireMsgExecutors = Executors.newSingleThreadScheduledExecutor(new ThreadFactoryImpl("CleanExpireMsgScheduledThread_"));
}
- 主线程池执行的逻辑
@Override
public void submitConsumeRequest(
final List<MessageExt> msgs,
final ProcessQueue processQueue,
final MessageQueue messageQueue,
final boolean dispatchToConsume) {
final int consumeBatchSize = this.defaultMQPushConsumer.getConsumeMessageBatchMaxSize();
//1. msgs是一批消息,先判断这一批消息是否大于最大处理量
if (msgs.size() <= consumeBatchSize) {
ConsumeRequest consumeRequest = new ConsumeRequest(msgs, processQueue, messageQueue);
try {
//2. 放入正常队列执行业务上的消费逻辑
this.consumeExecutor.submit(consumeRequest);
} catch (RejectedExecutionException e) {
//3. 消费失败,放入延迟等待线程池中
this.submitConsumeRequestLater(consumeRequest);
}
} else {
//4. 如果batch消息太多会按照最大消费长度分批进行处理
for (int total = 0; total < msgs.size(); ) {
List<MessageExt> msgThis = new ArrayList<MessageExt>(consumeBatchSize);
for (int i = 0; i < consumeBatchSize; i++, total++) {
if (total < msgs.size()) {
msgThis.add(msgs.get(total));
} else {
break;
}
}
//重复2、3的逻辑
ConsumeRequest consumeRequest = new ConsumeRequest(msgThis, processQueue, messageQueue);
try {
this.consumeExecutor.submit(consumeRequest);
} catch (RejectedExecutionException e) {
for (; total < msgs.size(); total++) {
msgThis.add(msgs.get(total));
}
this.submitConsumeRequestLater(consumeRequest);
}
}
}
}
消费的逻辑:
- 创建三个不同的线程池分别是正常消费的线程池、等待消费的线程池、清理消息的线程池
- 判断当前消息数量是否大于最大处理数量
- 尝试使用正常消费的线程池进行消费 如果失败 -> 等待消费的线程池
消费消息线程池的逻辑
- ConsumeRequest
- 线程调用消息的处理逻辑,根据消息从处理逻辑返回结果进行下一步操作
- 调用消息的逻辑
ConsumeReturnType returnType = ConsumeReturnType.SUCCESS;
try {
if (msgs != null && !msgs.isEmpty()) {
for (MessageExt msg : msgs) {
MessageAccessor.setConsumeStartTimeStamp(msg, String.valueOf(System.currentTimeMillis()));
}
}
//listener就是消息的处理逻辑方法
status = listener.consumeMessage(Collections.unmodifiableList(msgs), context);
} catch (Throwable e) {
log.warn("consumeMessage exception: {} Group: {} Msgs: {} MQ: {}",
RemotingHelper.exceptionSimpleDesc(e),
ConsumeMessageConcurrentlyService.this.consumerGroup,
msgs,
messageQueue);
hasException = true;
}
- 处理消息的逻辑
switch (status) {
case CONSUME_SUCCESS:
if (ackIndex >= consumeRequest.getMsgs().size()) {
ackIndex = consumeRequest.getMsgs().size() - 1;
}
int ok = ackIndex + 1;
int failed = consumeRequest.getMsgs().size() - ok;
this.getConsumerStatsManager().incConsumeOKTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), ok);
this.getConsumerStatsManager().incConsumeFailedTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), failed);
break;
case RECONSUME_LATER:
ackIndex = -1;
this.getConsumerStatsManager().incConsumeFailedTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(),
consumeRequest.getMsgs().size());
break;
default:
break;
}
switch (this.defaultMQPushConsumer.getMessageModel()) {
case BROADCASTING:
for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) {
MessageExt msg = consumeRequest.getMsgs().get(i);
log.warn("BROADCASTING, the message consume failed, drop it, {}", msg.toString());
}
break;
case CLUSTERING:
List<MessageExt> msgBackFailed = new ArrayList<MessageExt>(consumeRequest.getMsgs().size());
for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) {
MessageExt msg = consumeRequest.getMsgs().get(i);
boolean result = this.sendMessageBack(msg, context);
if (!result) {
msg.setReconsumeTimes(msg.getReconsumeTimes() + 1);
msgBackFailed.add(msg);
}
}
- 将不同返回值的消息写入不同的队列中
- 根据不同的消费方式做不同的处理
2.1 广播模式 消费不成功不处理
2.2 集群模式消费不成功,推送broker,让broker通知其他consumer进行消费,还是失败进入延迟队列
ProcessQueue
ProcessQueue是consumer中每一个MessageQueue所对应的队列消耗快照。
private final ReadWriteLock lockTreeMap = new ReentrantReadWriteLock();
private final TreeMap<Long, MessageExt> msgTreeMap = new TreeMap<Long, MessageExt>();主要是由一个TreeMep和ReadWriteLock锁组成,TreeMap里以MessageQueue的Offset作为Key,以消息内容的引用为Value,保存了所有从MessageQueue获取到但是还未被处理的消息,读写锁控制着多个线程对TreeMap对象的并发访问。
总结
Consumer的消费过程是:
- 根据配置信息初始化Consumer client对象
- 获取Offerset偏移量
- 获取BrokerTable中的地址
- 调用NettyRemotingClint获取消息,然后业务处理完成回调
Consumer的消费的组件是:
- 处理正常消费的消息线程池
- 处理延迟消息的线程池
- 清理消息的线程池
每一个MessageQueue在消费时都有一个ProcessQueue来缓冲所有已消费未处理的消息,ProcessQueue底层是采用TreeMap、ReadWriteLock来进行实现的

