基本数据结构
| 类型 | 特点 |
|---|---|
| string | 字符串 |
| list | 列表 |
| set | 不重复列表 |
| hash | 哈希 |
| zset | 有序集合 |
Redis中的hash是渐进式hash,不会在扩容时暂停,而是会重新创建一个新的hash来保存
基础操作
字符串
| 序号 | 命令 | 功能 | 示例 |
|---|---|---|---|
| 1 | SET key value [EX seconds|PX milliseconds|KEEPTTL] [NX|XX] | 设置字符串 | set key value |
| 2 | GET key | 获取字符串 | get key |
| 3 | EXISTS key [key …] | 判断是否存在 | exists key |
| 4 | DEL key [key …] | 删除key | del key |
列表
| 序号 | 命令 | 功能 | 示例 |
|---|---|---|---|
| 1 | RPUSH key element [element …] | 装载元素 | rpush list item0 |
| 2 | LLEN key | 返回长度 | LLEN list |
| 3 | LPOP key | 弹出第一个元素 | LPOP list |
| 4 | RPOP key | 弹出最后一个元素 | RPOP list |
| 5 | LINDEX key index | 根据索引查询元素 | LINDEX list 0 |
| 6 | LRANGE key start stop | 按照范围获取元素 | lrange books 0 -1 |
| 7 | LTRIM list start stop | 截取list | LTRIM list 0 1 |
hash(字典)
| 序号 | 命令 | 功能 | 示例 |
|---|---|---|---|
| 1 | HSET key field value [field value …] | 装载元素 | hset map key value |
| 2 | HGET key field | 获取指定元素 | hget map key |
| 3 | HGETALL key | 获取全部元素 | hgetall map |
| 4 | HLEN key | 获取map长度 | hlen map |
set(集合)
| 序号 | 命令 | 功能 | 示例 |
|---|---|---|---|
| 1 | SADD set key… | 装载元素 | sadd set item1 |
| 2 | SMEMBERS set | 获取全部元素 | smembers set |
| 3 | SCARD set | 获取set长度 | scard set |
| 4 | SPOP set | 弹出元素 | spop set |
zset(有序集合)
| 序号 | 命令 | 功能 | 示例 |
|---|---|---|---|
| 1 | ZADD key [NX|XX] [CH] [INCR] score member [score member …] | 添加元素 | zadd books 9.0 “think in java” |
| 2 | ZRANGE key start stop [WITHSCORES] | 按照元素范围取值 | zrange books 0 -1 |
| 3 | ZREVRANGE key start stop [WITHSCORES] | 倒序取值 | zrevrange books 0 -1 |
| 4 | ZCARD key | 获取长度 | zcard books |
| 5 | ZRANK key | 获取分数 | zrank books |
| 6 | ZRANGEBYSCORE key start stop | 根据分值区间遍历 | zrangebyscore key 0 -1 |
| 7 | ZREM set key | 删除元素 | zrem books item1 |
运维
| 序号 | 命令 | 功能 | 示例 |
|---|---|---|---|
| 1 | keys | 根据正则匹配查询(慎用) | keys * |
Redis删除过期Key的策略
- 将具有过期时间设置的key放在一个特殊的队列中
- 每秒扫描10次进行过期key的删除操作
2.1 随机从过期的key中获取20个数据
2.2 判断key是否过期,过期进行删除
2.3 如果筛选出来的数据有超过1/4需要删除,那么重复进行2.1的操作
由于Redis在执行删除操作时会阻塞主线程,因此在’set key nx’时需要注意key的过期时间,尽量避免大量的key在同一时间删除,阻塞业务
这种删除方式称为’主动删除’,还有一种删除方式是在使用时check时间,当超时时会进行删除这种方式被称为’惰性删除’
Redis的淘汰策略
- 不接受write请求,保持现有key(默认策略)
- LRU策略
2.1 过期时间(淘汰设置过期时间的key,按照最少使用的原则)
2.2 剩余时间(淘汰剩余时间最小的时间)
2.3 过期时间(按照随机的方式进行淘汰)
2.4 全部key(按照最少使用的原则进行淘汰)
2.5 全部key(随机淘汰)
小结:Redis淘汰key的范围主要有两种’过期key’和’全量key’,筛选策略主要有两种:‘时间/使用频率’和’随机’
大key查询
./redis-cli --bigkeys -i 0.01原理分析
字符串
数据结构
Redis的字符串结构底层是通过’数组’来实现的,数据格式分为两种类型:
- emb格式
针对容量较小的字符串采用的是emb格式,emb的特点是数据的元数据和内容在内存上是连续的.这样做的好处是节省了元数据的空间 - raw格式
针对普通数据采用的是raw格式,这种格式在记录元数据和内容在内存上不是连续的,需要经过两次内存分配,好处是空间可以较大,但是元数据占用空间较多
猜测redis最开始应该是不支持emb格式的,但是由于redis在使用时,大部分场景下都是存储较小的字符串,因此后来才支持emb这种格式的.由于大部分是小字符串因此这样的改动会优化很大一部分内存空间
dict(字典)结构
dict是Redis内部使用最频繁的结构,由于Redis在是在初始化dict时进行内存分配,因此在扩容时采用的是’渐进式’扩容的方式.
Redis的渐进式扩容需要用到另外一个hashtable,在迁移数据的过程中对于set操作会直接set到新的hashtable上,对于put操作会对两个hashtable进行查找
扩容默认的阀值是需要达到原hashtable的长度,才会对hashtable进行一倍容量的扩容.缩容的条件是数据不满数组长度的1/10时
跳跃列表结构
跳跃列表是实现zset的关键,zset是由hashtable和跳跃列表这两种数据结构组成
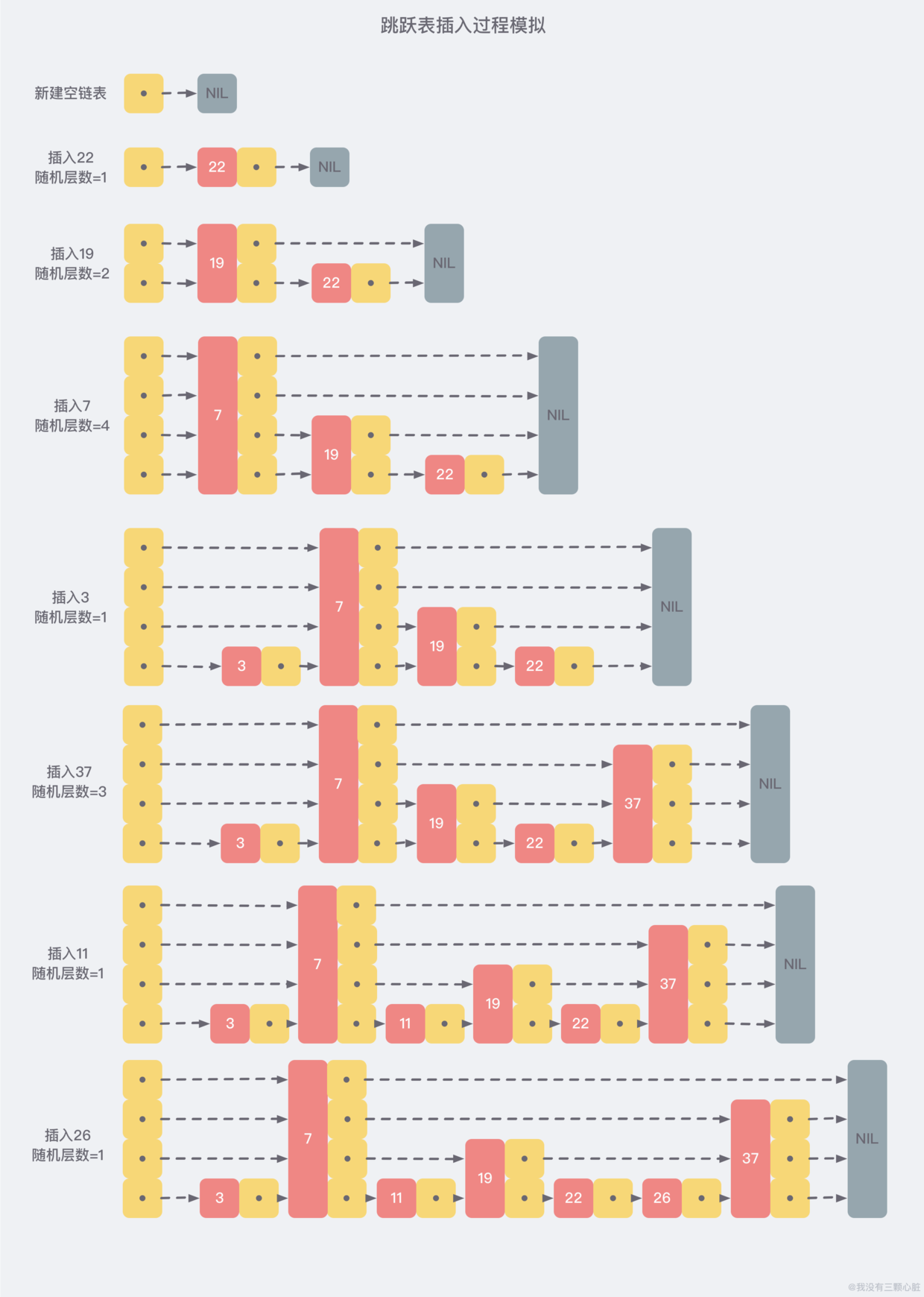
- 这里要注意一下,跳跃表查询的时间复杂度是O(log(n))与二分法的时间复杂度类似,跳跃表是底层数据结构并不是查询算法这里需要额外注意一下.zset的底层数据结构选择跳跃表的原因大概是因为跳跃表数据结构简单,并且在层级随机的前提下性能还行,并且支持范围查询,这是红黑树/ 平衡树所不能支持的,
- 跳跃列表的更新分为两个步骤,先删除原来的节点,在将新的节点插入跳跃列表中
示例
redi分布式锁
实现原理
redis分布式锁实现的原理是,多个进程同时竞争同一个共享资源,拥有这个资源的线程就可以执行,其他进程等待执行线程释放。
问题
加锁:
- set和get是两个命令,因此要用set nx
- 不会自动过期,因此要用px,设定过期时间
- 无法标记执行线程,因此要设置redis唯一值
SET resource_name my_random_value NX PX 30000解锁:
解锁需要判断线程持有的随机值和redis的值是否一样,因此要使用lua脚本
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end在只是单机版redis的分布式锁,不适合分布式环境。当redis宕机后,执行线程不会被释放。当线程执行耗时任务时,可能出现redis释放锁,其他线程持有锁。
分布式redis锁可以采用Redission实现,底层是redis作者实现的Redlock原理。
- 关于RedLock存在的问题
- 对获取到锁的进行操作没有保护机制,这里其实可以对比过期时间的方式来处理
- RedLock是建立在时间有序的前提下的
一般业务系统可以使用RedLock算法,在严格要求分布式锁正确性的场景下推荐使用ZK(curator已有现成实现)
注意事项
-
缓存雪崩
雪崩指的是大量key在同一时间失效,导致大量请求发送到后端,影响数据库的情况
在设计key时就要考虑到失效时间的影响,将时效时间拉成一个时间段将请求进行防范 -
缓存穿透/击穿
缓存穿透/击穿指的是请求的key不在cache中,导致大量请求发送到后端系统中
解决这种问题需要从三个方面进行处理:
1.业务接口的设计上做到只提供最小范围(可控可知)的入参,尽量避免出现缓存穿透的情况;
2.对于恶意的请求可以通过Nginx这些反向代理工具进行隔离,也可以通过业务网关进行隔离
3.做好对出现穿透后的异常检测和恢复机制,可以使用Hystrix进行限流和降级
Cache使用策略
- 查询步骤
user -> cache -> DB - 更新步骤
user -> DB(update) ->cache(delete)
一般使用cache都是使用这种策略,这种策略可能出现的问题是一个操作持有修改前的数据,但是在另外一个操作对数据进行修改后才将数据放到cache中;这种问题出现的概念较低,可以为缓存设置失效时间来尽可能的避免影响范围.还有的设计方案是让cache直接去维护DB的数据修改核心思想就是将两个写操作入口合并成为一个,从而解决数据不一致问题;
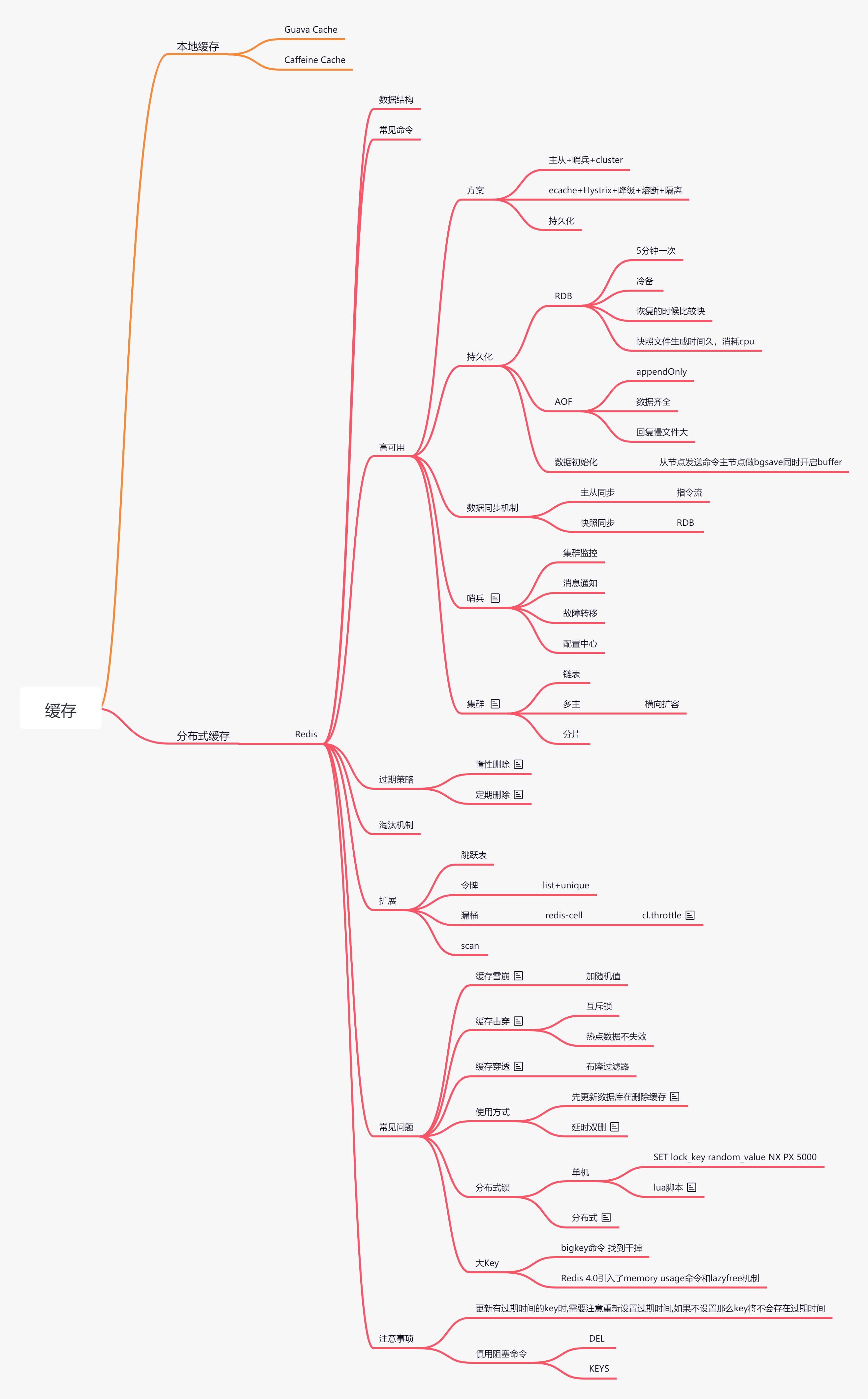
总结
参考资料
Redis在线教程
Redis(2)——跳跃表
Redis 设计与实现
思维导图地址
关于Redis分布式锁的争论
使用Redis的分布式锁
Redlock安全吗

